
7 The encoding question
7.1 Introduction to Presentation Layer concepts
Again we require something of a mind-shift in looking at the Presentation Layer, compared with either the Transport or the Session Layers. In the Transport Layer we saw a very simple set of service primitives, supported by a number of different protocols, with the only effect of using one or other of these being on the quality of the resulting service. In the Session Layer, we saw a lot of added value through the provision of a whole set of largely independent service primitives, each supported by its own piece of protocol. In the Presentation Layer, by contrast, we see only one new (confirmed) service, the P-ALTER-CONTEXT request/indication, response/confirm, supported by protocol, with all other actions related simply to transformation of user data parameters on primitives closely paralleling those of the Session Layer.
The reader may wish to review clause 2.4.6, which identifies the concerns of the Presentation Layer, and the reasons for permitting a varying representation of data in different instances of communication.
The P-ALTER-CONTEXT service primitives are concerned with negotiating the representation to be used, but all other P-service primitives are a simple reflection of the S-service primitives. For every S-service primitive in the Session Layer, there is a P-service primitive with an identical set of parameters (for example P-SYNC-MAJOR). The rules for when these P-primitives can be issued are precisely those of the session service, and the protocol supporting these service primitives is in almost all cases a simple and direct mapping between the P-service and S-service primitives (in both directions). What then is the added value?
The critical difference is in the nature of the user data parameter of each of the primitives. In the Session Service, the user data parameter of each service primitive is an (unlimited size - remember?) string of octets. Specifying its value is a matter of clearly specifying the value of these octets. In the Presentation Service, however, the user data parameter is pure information, divorced of any representation. The presentation protocol machine generates an appropriate (agreed by negotiation) octet string for the Session Service to carry this information during transfer, and decodes a received octet string to produce pure information on receipt, for passing up in the Presentation Service primitive.
This can be a hard concept to grasp, particularly for those who view layering as an implementation architecture. It is clearly rather hard to pass pure information divorced of representation in a real implementation interface, and people sometimes say that "The Presentation Layer maps from a local representation to an agreed transfer representation", because that is what some piece of code somewhere in the implementation will actually be doing. It is, however, an inappropriate model as it would imply that application layer standards specify values in some local representation - clearly a nonsense. Local representations of information are part of the implementation, and have no visibility in standards work.
7.2 Abstract and transfer syntaxes
The reader will be asking "But what is pure information, and how does an application layer designer specify a value for pure information?" This is quite a hard question to answer.
It can help to clear the mind to consider some aspects of information theory. If a set of known values are to be transmitted, with each one being transmitted at random (no dependencies on what was last transmitted), and the probability of transmission of a particular value is known, then the (provably) optimal encoding for transmission uses a number of bits for each value which is inversely related to the probability of its transmission. Thus if one value occurs very often, that would be represented by a single zero bit (say), and all other values would be represented by a pattern starting with a one bit. Values that occurred very infrequently would be represented by a bit pattern containing a great many more bits, depending on the total number of values in the set.
Thus we see that the focus is on values as a set of things that need to be represented (by an arbitrary but unambiguous) string of bits. Any piece of information to be transferred is either identical to some other piece of information (indistinguishable from it), in which case it is the same value, or differs in some aspect, in which case it is a different value. We are not here concerned with looking at internal structure. A piece of information consisting of a list of six integers has values that we can represent on paper (in this book) as (for example) {39, -26, 5, 78, 81, 0}, which is one single value of this information, and {39, -26, 5, 79, 81, 0} is another single value. There is no concept that this second value might be considered nearer to the first than, for example, {1023, 87, 234, -456, 56, 9}: that depends on looking inside the single value, something we do not necessarily wish to do.
For any particular protocol design, it is at least possible to consider the theoretical set of all possible values of the information it wants to send in the user data of presentation service primitives. This may be an infinite set of values (like those specified above), but it nonetheless must be a well-defined set of values if the protocol is well-specified.
We talk about the set of presentation data values for this application protocol as this collection of values, and we give a name to this collection. We call it the abstract syntax of the protocol. So application protocol designers specify their abstract syntax (somehow - formal notation, ordinary English, whatever).
An abstract syntax then is a collection of presentation data values (sometimes just called data values, and sometimes just called values, or abstract values) to be transferred by the Presentation Layer in the operation of some particular protocol.
In order for the presentation protocol machine to convert such abstract values into bits for the session layer to transfer, it is necessary to have associated with this abstract syntax (this collection of presentation data values) a set of bitstrings. This set of bitstrings is called a transfer syntax for this abstract syntax is called a transfer syntax for this abstract syntax syntax (set of bitstrings) for an abstract syntax has the following properties:
- For each (presentation) data value in the abstract syntax there is one or more bitstrings in the transfer syntax associated with that value.
- Each bitstring in the transfer syntax is distinct, and has precisely one abstract value associated with it.
In other words, the transfer syntax provides bitstrings that unambiguously (but not necessarily uniquely) represent the abstract values (presentation data values) in the abstract syntax with which it is associated. Where there is more than one bitstring in the transfer syntax associated with some particular abstract value, then it is an implementation option which one to use in any particular transfer. If a transfer syntax has a single bitstring for each abstract value, we call it a canonical transfer syntax. (The importance of canonical transfer syntaxes is discussed later, but relates to security issues.)
The reader should at this stage note that there are two further potential requirements that are not a requirement on a well-formed transfer syntax. First, the bit-patterns representing an abstract value are not required to be a multiple of eight bits, they can be any length, and secondly they are not required to be self-delimiting. The precise meaning of this latter point is discussed below, but both features impose requirements on the design of the presentation protocol which the reader may wish to think about.
In order to support the concept of differing representations of presentation data values and Presentation Layer negotiation of the representation, we need two additional features:
- We need to recognise that any particular abstract syntax may have more than one defined transfer syntax associated with it, providing alternative means of encoding (representing) the abstract values.
- We need a means of identifying abstract syntaxes and transfer syntaxes with names (identifiers) that can be used to refer to them in the presentation protocol negotiation of which transfer syntax to use.
It is important that the name-space for naming abstract and transfer syntaxes should permit allocation of identifiers by any group likely to be defining OSI application layer protocols, and by any computer vendor or other implementor that wants to define vendor-specific transfer syntaxes (optimised for communication between that vendor's implementations). This requirement was satisfied by work within the group charged with standardising a notation which could be used for abstract syntax definition. This form of name is called an ASN.1 OBJECT IDENTIFIER, and it is discussed more fully in the later chapter on ASN.1 (Abstract Syntax Notation One) - Chapter 8. Its use is much wider than the simple naming of abstract and transfer syntaxes, which is why it is called an object identifier, rather than a syntax identifier, but its use to identify unambiguously abstract and transfer syntaxes is the only concern in this chapter.
7.3 Data transfer requirements placed on the Presentation Layer
It might be assumed that, for any particular presentation connection, there will be a single abstract syntax in use, corresponding to the application protocol running over that connection. However, there are two reasons why this approach proved too simplistic and limiting.
- First of all, any particular group defining a protocol may find it convenient to group some of their values into one abstract syntax, and some into another. Thus for example, in the case of FTAM (File, Transfer, Access and Management), there are values to be transmitted which are part of the main protocol, saying things like "open file x", "write to it", and so on. There are also values to be transmitted which are the values to be stored in some particular type of file (for example, lines of characters from some defined repertoire for a simple character file). Clearly it makes sense to define an abstract syntax for the main protocol, and separate abstract syntaxes for each type of file that we might be concerned with. Depending on how many files are open, and what type they are, there may be a need to transfer values from several abstract syntaxes (an arbitrary number) in a fairly random sequence within a single presentation connection.
- Secondly, the concept of Application Service Elements (discussed in chapter 9) recognises that the total information transfer to completely support an application may be made up of parts defined by a number of different groups, each defining an Application Service Element, and hence each with an information exchange requirement. It avoids a large number of potential liaison problems in ensuring unambiguous transfer syntaxes if each of these groups can operate independently and define separate abstract syntaxes, with values from the abstract syntaxes of any of the Application Service Elements in use being transferred over the presentation connection.
There are two other complications to consider:
- First, Application Service Elements frequently define a protocol as the transmission of presentation data values that have holes in them. This is actually just the normal situation with layering. The Application Service Element provides some form of carrier service, and other Application Service Elements provide their own presentation data values to fill in the holes. The question of holes (often called black holes) is discussed more fully later, but for the present all that matters is to recognise that, early in its development, the Presentation Layer recognised the concept that a presentation data value might have embedded within it presentation data values from some other abstract syntax (to arbitrary depth).
- The second complication arises because it can happen for some applications that the same abstract syntax (the same set of abstract values) is used in two different circumstances which require to be distinguished, and which perhaps require different encodings. Let us look at the FTAM example again. Suppose we have set up monitoring (to some log file) of the main protocol exchanges in some instance of use of FTAM. This file will have a contents that is a series of values from the main FTAM abstract syntax, but it is clearly important (if this file is later accessed using FTAM) that such values are not confused with values forming the main FTAM protocol (designed to open, write, read, files etc) in this particular communication. Moreover, it might be desirable under some circumstances (for example where implementations from the same vendor are communicating) for the transfer syntax for these values when they are values in the log file to be a vendor-specific one closely related to the way they are stored on disk, whilst the transfer syntax for these values when they form part of the main FTAM protocol exchange might be some internationally standardised or more highly optimised transfer syntax, but anyway, different. These considerations give rise to the concept of a presentation context.
A presentation context is defined as an association between an abstract syntax and an associated transfer syntax. In other words, it is a set of presentation data values (those in the abstract syntax) for which a transfer syntax has been agreed, and which represents an instance of use of an abstract syntax on some presentation connection. To fulfil the requirements discussed above, we recognise that any one given abstract syntax may have multiple instances of use (multiple presentation contexts, with the same or with different transfer syntaxes), and that the basic unit of data transfer should be the transmission of a presentation data value from some identified presentation context. At any point in time on a connection, a number (potentially unlimited) of presentation contexts will have been agreed for use (defined), and values from any of these contexts can be transferred. This set of presentation contexts is called the defined context set (DCS).
So .... with these concepts in place, what are the main requirements to be placed on the presentation layer? First, it should support the attempt by an application to define a new presentation context for some named abstract syntax, negotiating the transfer syntax to be used for that presentation context. (It may also be useful to allow deletion of contexts from the defined context set.) Secondly, it should support the transfer (in the user data parameter of each Presentation Service primitive) of a list of presentation data values, each one from a different (potentially) presentation context in the defined context set, and possibly containing embedded presentation data values from some other presentation context. Thirdly, it must define an appropriate protocol to support that transfer.
The second requirement is simply met by defining the user data parameter of each Presentation Service primitive in precisely that way: as an ordered list of presentation data values from any presentation context in the defined set (defined at the time the Presentation Service primitive is issued). The alert reader, however, will already have some alarm bells beginning to ring. It is clearly rather important that any changes to the defined context set are managed in such a way that if a presentation data value from some context is present on a request or response service primitive, then that context must (still) be part of the defined context set when the message reaches the remote system, and the corresponding indication or confirm is issued. This begins to look a bit like the dialogue separation requirement of session, and one solution could have been to require that all changes to the defined context set coincide with a major synchronization. That solution, however, is clearly not acceptable, given the possible use of activities without major synchronization, and the concerns discussed earlier about the efficiency of major synchronization when using TP4. The problem will be discussed when the negotiation of contexts (the first requirement above), and the supporting protocol (the third requirement above) are discussed below.
Another problem relates to embedded presentation values. It can be the case that a presentation data value (at the outer level, say) carrying an embedded presentation data value, is relayed with little understanding of its form or transfer syntax by the relay system. This requires some care in the way in which embedded values are handled, and introduces the concept of a relay-safe transfer syntax, which is discussed more fully later in chapter 8.
7.4 Establishing the defined context set by negotiation
In the simplest case, all contexts to be used on a connection will be negotiated and agreed as part of the initial exchange of messages that are piggy-backed on the S-CONNECT exchange as described earlier. There will be no additions or deletions to that set of contexts during the life-time of the connection, and the concerns about encoded data crossing with or overtaking changes to the defined context set do not arise. This is part of the kernel presentation functional unit. The ability to add to the defined context set and delete contexts during a connection using the P-ALTER-CONTEXT service primitives is part of what is called the context management functional unit, and as for the Session Layer, its availability is negotiated at the time the connection is established.
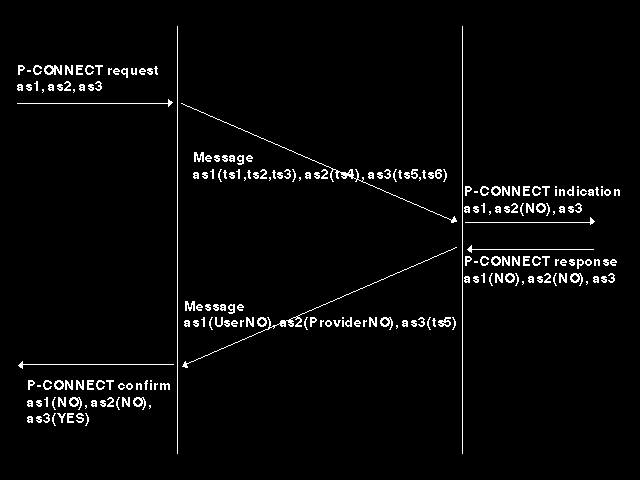
To establish contexts at connection establishment time, the procedure is as shown in figure 7.1: Establishing contexts on P-CONNECT. Notionally, all concern with the transfer syntax is a Presentation Layer matter (the application designer does not specify transfer syntaxes), so the P-CONNECT request carries only (as far as presentation context negotiation is concerned) an ordered list of abstract syntax names for which presentation contexts are to be established. It does not mention the transfer syntax to be used.
{kind=link}
Despite this formal position as far as the model and the service definition are concerned, agreement was reached in the middle 1980s (but nowhere documented in any standard) that application designers were free to specify static conformance requirements for transfer syntaxes (that is, the ones that all implementations had to support), and many application layer standards do indeed specify mandatory implementation of transfer syntaxes produced using the so-called ASN.1 Basic Encoding Rules (discussed later) in order to ensure interworking for those applications.
When the P-CONNECT request is issued, the presentation layer then notionally forms the message supporting the P-CONNECT (and which forms the user data parameter of the S-CONNECT that is to be issued). That message contains inter alia a data structure consisting of the list of abstract syntax names, with each one having associated with it a list of one or more transfer syntax names that are being offered as candidates for agreement to support that abstract syntax.
We said "notionally" again, for implementation structure is not constrained by OSI standards, nor is it visible on the line. All that matters is that the total implementation (with full knowledge of the use that is to be made of each presentation context) offers one or more transfer syntaxes for each required presentation context. Note also that, to support the establishment of multiple contexts for the same abstract syntax, the list of abstract syntax names is an ordered list, and the same abstract syntax name may appear more than once.
Clearly, an implementation will not offer transfer syntaxes that it does not support, but there is no requirement that it should offer all those that it does support, if other information makes it inappropriate to do so.
On receipt of the S-CONNECT indication carrying this message, the presentation layer notionally flags as not available (rather than removing) any abstract syntax in the list for which there is no offered transfer syntax that it can support and then issues a P-CONNECT indication to the application layer containing the list. (The question of identification of the application to which this is notionally addressed - FTAM, X.400, or whatever - is discussed in a later section.)
The application then determines which contexts are to be established by further flagging items in the list as not established before returning the list on the P-CONNECT response. The protocol machine now adds precisely one transfer syntax name for each context which is to be established, and returns (as user data of the S-CONNECT response) a message which informs the originating implementation of the contexts that have been established, and the list of which contexts have been established and which have not is passed up to the application. For those not accepted, there is an error code that determines whether the context was refused by the provider (and if so whether this was because there were too many in the DCS, no offered transfer syntax was supported, or the abstract syntax was not supported) or by the user.
There is thus a limited form of negotiation available to the application designer: it is possible, for example, to specify that an attempt be made to establish a presentation context for each of a number of abstract syntaxes, and to specify that the receiving application should choose one of these for establishment and reject the rest. More commonly, however, each presentation context in the list will be accepted, and the negotiation is entirely confined to establishing (within the presentation layer) the transfer syntax to be used for each one.
The message actually carries with each presentation context proposed for definition an odd-numbered integer value (the reason for using only odd-numbered values is given below in the discussion on collisions). This value forms the presentation context identifier and is associated with bit-patterns transmitted later to identify the presentation context of the presentation data value they represent (and hence specifying how to map them into an abstract value).
7.5 The supporting protocol
7.5.1 Generating the Session Service user data parameter
The Presentation Service user data parameter contains an ordered list of presentation data values, each being a value from the defined context set. The encoding of that value into a bit-string is well-defined by the well-formed transfer syntax associated with the presentation context. Moreover, we assume that the handling of embedded presentation data values is the responsibility of the designer of transfer syntaxes supporting such structures, and no direct support is provided in the Presentation Layer protocol. (Again, further discussion on this issue appears in chapter 8.).
Now the bit-pattern defined by the transfer syntax has three deficiencies in terms of simple mapping to the Session Service:
- It is not a multiple of eight bits, and the Session Service user data parameters are all required to be octet strings (a requirement which reflects the requirements of X.25 and hence of the Network Service and Transport Service).
- It is only unambiguous in relation to other bit-strings in the same presentation context. The same bit-string can (and frequently will) appear in several transfer syntaxes (presentation contexts) with totally different abstract values (typically from different abstract syntaxes).
- It is not self-delimiting.
Let us address the last point first, as it has only recently become clearly understood in standards work.
A transfer syntax may be "hand-crafted" - manual design of the bit-patterns in it - but it is far more common for it to be defined by the specification of general purpose encoding rules that can be applied to any abstract syntax that has been specified using some defined notation with which the encoding rules are associated. We say that the notation defines a type (or data type, or data structure, or abstract type) whose set of values forms and defines the set of abstract values in the abstract syntax. In this case, the encoding rules may have been designed so that, without any knowledge of the type used to define the abstract syntax, the end of each bit-pattern can be determined using only a knowledge of the encoding rules themselves. Such encoding rules were considered in the past to produce self-delimiting encodings, but it is important here to note that such encodings are only "self-delimiting" if the process trying to delimit them does indeed have full knowledge of the applicable encoding rules. It is also important to note that the process of finding the end may be very simple (some sort of length count at the head of the encoding), or could be arbitrarily complicated, but still theoretically possible using only knowledge of the encoding rules. The next step along the sliding scale to not being self-delimiting is where the end cannot be determined from encoding rules alone, but requires a knowledge of the type used to define the abstract syntax (full knowledge of the abstract and transfer syntaxes). Thus, for example, the length of each bit-string in the transfer syntax may be the same provided the set of abstract values is the set of values of a fixed length character string, but not otherwise. Going further along the spectrum, we might have a transfer syntax (for example, the simple ASCII encoding of a variable length character string, with no length count or delimiter) such that, if the encodings of two different values are concatenated, then a receiver has no way of determining where the boundary lies, and ambiguity would arise in the decoding process.
This discussion has been intended to bring out the point that self-delimiting is an ill-defined term, but as a minimum requires knowledge of some specific encoding rules. It was, in retrospect, unfortunate that throughout the 1980s a single notation (ASN.1) and one single set of encoding rules (Basic Encoding Rules) was almost universally used in the definition of abstract and transfer syntaxes, and that the Basic Encoding Rules did indeed provided relatively easy determination of the end of an encoding without knowledge of the type used to define the abstract syntax. Thus the idea of a self-delimiting transfer syntax, as a fundamental property of a transfer syntax gained credence.
Again, the ASN.1 Basic Encoding Rules always produced bit-strings that were a multiple of eight bits - again a property of the transfer syntax that a process decoding it would only know by having knowledge of those Basic Encoding Rules. This led to the concept of an octet-aligned transfer syntax, but this suffers from similar problems to the concept of self-delimiting. "Octet-aligned" can be given meaning in relation to a specific transfer syntax (every value is a multiple of eight bits), but an encoding rule may produce an octet-aligned transfer syntax for some abstract syntaxes and not for others.
The protocol defined in the Presentation Layer is itself specified using the ASN.1 notation and applying the Basic Encoding Rules. It is thus not inappropriate to assume a knowledge of these encoding rules within all implementations, and to optimise for the self-delimiting and octet-aligned nature of these encodings. A not-yet-resolved (1995) defect report on the Presentation Layer protocol points out that the text currently uses these two terms (which are, as discussed earlier, hard to define), and optimises in cases where a receiver may not have enough knowledge of a transfer syntax to determine the end of an encoding, or even to determine if it is octet-aligned. The proposed resolution of the defect is to avoid use of these terms, and to optimise specifically and only for transfer syntaxes defined using the Basic Encoding Rules, which has strong properties, and which it can be assumed is universally implemented.
The reader may be asking "How can an implementation determine from a transfer syntax OBJECT IDENTIFIER that it has been generated using the ASN.1 Basic Encoding Rules?" The answer is that such transfer syntaxes are all identified by the same OBJECT IDENTIFIER: assigned to the Basic Encoding Rules. (Remember that a transfer syntax OBJECT IDENTIFIER only really needs to be unambiguous within the scope of an abstract syntax OBJECT IDENTIFER, so this approach gives no problems.) Thus basing Presentation Layer protocol optimization on the use of this OBJECT IDENTIFIER is valid.
With that preamble then, what is the general form of the mapping from a list of presentation data values to the Session Service user data parameter?
In the general case, each presentation data value is mapped to a bit-string using the negotiated transfer syntax. That bit-string is then made octet-aligned and self-delimiting by wrapping length and bit counts around it, and the presentation context identifier (an integer, also made self-delimiting by wrapping a length count round it) is added to the head of it. These encodings for each presentation data value in the list are then appended to each other, and the whole sequence has a further length count placed in front of it, producing the set of octets that forms the Session Service user data. There are clearly interesting design (encoding) issues within the Presentation Layer about the form of length counts to handle arbitrarily large lengths. These were actually resolved by using the ASN.1 notation to define a data structure to handle the general case, a slightly simplified form of which is:
SEQUENCE OF SEQUENCE {
context-id INTEGER,
encoding BIT STRING
}
and then applying the Basic Encoding Rules to that. (The meaning of the above piece of ASN.1 should be clear to the reader from what has gone before, but a more detailed treatment appears below.) Note that the concepts of abstract and (negotiated) transfer syntax only apply to things above the Presentation Service. The use of ASN.1 and its Basic Encoding Rules in the Presentation Layer protocol is nothing more than a convenient short-hand for defining a fixed bit-pattern for the protocol.
There are clearly significant overheads in this process if every presentation data value in the user data parameter is from the same presentation context, and has a transfer syntax obtained by applying the ASN.1 Basic Encoding Rules (already self-delimiting - given knowledge of these encoding rules - and octet-aligned). In this case, there is an optimization that permits a presentation context id to be encoded, followed by a count of presentation data values from that context, followed by the transfer syntax encoding (self-delimiting and octet-aligned) of a series of presentation data values from that presentation context, followed (if necessary) by further sequences of this sort. Note that in this case, the end of the resulting Session Service user data parameter can only be determined by a receiver using the lower layer delimitation mechanisms (which fundamentally rest on the bit-stuffing of the Data Link Layer), and cannot be determined from any encoding produced by the Presentation Layer.
The reader should observe three points:
- The process of mapping is broadly simple: map to the transfer syntax bit-pattern, wrap it round to make it a self-delimiting octet string, add the presentation context identifier, repeat for the next presentation data value, and wrap the entire list up and pass to the Session Layer.
- The actual mechanisms and encodings when optimizations that are considered desirable are applied become quite complex.
- The optimizations in the initial standard (probably) have severe flaws once significant use is made of encoding rules other than the ASN.1 Basic Encoding Rules, but these have been (will be) addressed in amendments to the protocol before use of such additional encoding rules becomes widely implemented.
7.5.2 Support for negotiation
Negotiation of presentation contexts has been broadly described above. Again, an ASN.1 data structure is defined and the Basic Encoding Rules applied to determine the messages. The structure used to propose new presentation contexts is
SEQUENCE OF SEQUENCE {
context-id INTEGER,
abstract-syntax OBJECT IDENTIFIER,
transfer-syntaxes SEQUENCE OF OBJECT IDENTIFIER
}
with the reply being a similar message but with a single transfer-syntax. During a connection, this message is carried on the Session Service primitive designed to meet this need: the S-TYPED-DATA primitive, and is supported in the Presentation Service by the P-ALTER-CONTEXT request/indication response/confirm (the only new Presentation Service primitives). (The actual message used is slightly more complicated than that shown above, because a presentation context can also be deleted, and a proposed deletion can be refused.) A new presentation context is added to the defined context set at the responding end when the P-ALTER-CONTEXT response primitive is issued, and becomes available for use for presentation data values on that primitive or on later primitives. It is added to the defined context set at the initiating end when the P-ALTER-CONTEXT confirm primitive is issued.
The above messages also form part of the Presentation Layer protocol supporting the P-CONNECT service primitives (and mapping into the user data of the S-CONNECT service primitives) to establish an initial defined context set.
The alert reader should have spotted a small problem here. We said that the P-CONNECT primitives could also carry presentation data values to support the (perhaps negotiated) initialisation of the application. Like any other P-service primitive, the P-CONNECT primitives have a user data parameter that is a list of presentation data values. But at the time the P-CONNECT request is issued, there is nothing in the defined context set, and an agreed transfer syntax for these values is not available. For the P-CONNECT request (and the P-ALTER-CONTEXT request) only, the presentation data values are permitted to be from a context which is proposed for addition to the defined context set, rather than being restricted to ones that are already in that set. But what transfer syntax should be used to transfer such values?
The Presentation Layer protocol permits such values to be transferred using multiple encodings, potentially one for every transfer syntax proposed for the corresponding presentation context, tagged with the transfer syntax identifier for that encoding.
Of course, there is still no guarantee that such values can be successfully decoded by a receiving implementation. There has been a lot of discussion of this "data unreadable" problem within the standards community. In particular, the Presentation Service goes to great lengths to avoid the transfer of data that cannot be decoded. In this case, however, there is no option if we want to allow application data on this exchange. The application designer should assume that a presentation data value is delivered up, but it may not be possible to handle it in a way which requires it to be recognised and distinguished from other presentation data values in that abstract syntax. The modelling aspects of this situation have, however, never been properly resolved.
With this multiple encoding of an arbitrarily long list of presentation data values on the P-CONNECT primitives, the reader should now readily understand why the users of the Session Service said with one voice "WE WANT UNLIMITED USER DATA!"
7.5.3 Collisions
The reader may have hoped that we had left collision case problems in the Session Layer, but regrettably this is not so.
If there is no use of P-ALTER-CONTEXT (context definition only on P-CONNECT), then there are indeed no collision problems to be resolved and the Presentation Layer has no additional complicating features. In the presentation kernel functional unit, P-ALTER-CONTEXT is not available. This exchange becomes available if the presentation context management functional unit is agreed for use (using a negotiation on the P-CONNECT similar to that of S-CONNECT negotiation).
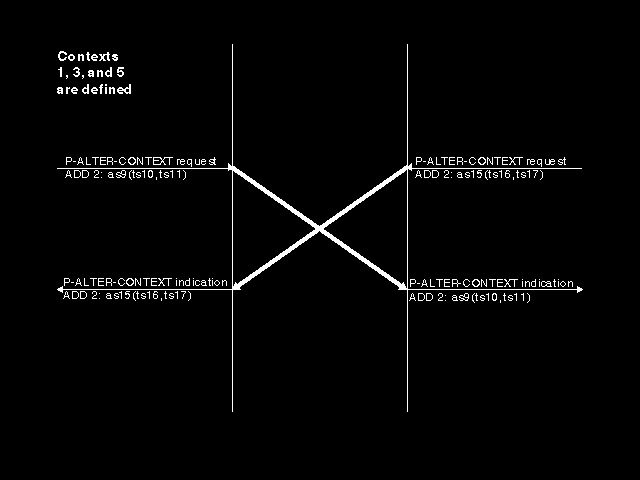
The first problem that arises is shown in figure 7.2: Contention for context identifier 2. In this case, we have contexts with identifiers 1, 3, and 5 already defined, and both sides now propose the addition of a context with an identifier of 2, but for different abstract syntaxes. Clearly this cannot be allowed to happen. The resolution is blindingly simple: the implementation that initiates a connection (where the P-CONNECT request is issued) only ever proposes the establishment (on the P-CONNECT request or on a P-ALTER-CONTEXT request) of presentation contexts with identifiers which are odd numbers, and the peer implementation (where the P-CONNECT indication is issued) only ever proposes the establishment (on a P-ALTER-CONTEXT request) of presentation contexts with identifiers which are even numbers. Thus the colliding P-ALTER-CONTEXT primitives can now be processed wholly independently, and make their own independent contribution to the defined context set.
{kind=link}
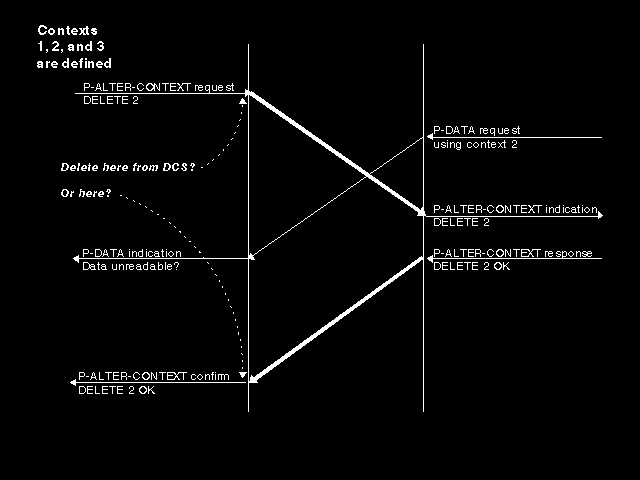
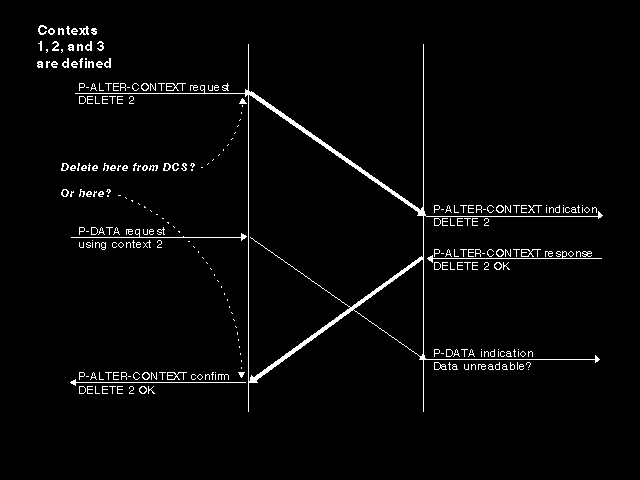
If we look at proposed deletions, we need to determine when actual removal from the defined context set (preventing use of that context for any subsequent presentation data value) is to occur, and we see some further problems. If we delete on the issuing of the P-ALTER-CONTEXT request, then the collision case in figure 7.3: P-DATA after context deletion can occur, whilst if we delete only when the confirm is issued the collision case in figure 7.4: P-DATA after context deletion (bis) can occur. This is resolved by deleting when the confirm is issued, but forbidding the use of contexts proposed for deletion between the issuing of the request and the arrival of the confirm.
{kind=link}
{kind=link}
The above collision cases were easy to resolve. A much more serious and interesting problem arises when a P-ALTER-CONTEXT exchange is disrupted by the purging effect of a session resync. Figure 7.5: Resync destroying P-ALTER-CONTEXT shows what can happen. Following the resync, we have a defined context set at application A which contains context 4, and one at application B which certainly cannot because the response/confirm exchange (carried on S-TYPED-DATA) saying which transfer syntax has been selected never arrived at the Presentation Layer (the S-TYPED-DATA indication did not get issued) because of the purging of dialogue one in the Session Layer.
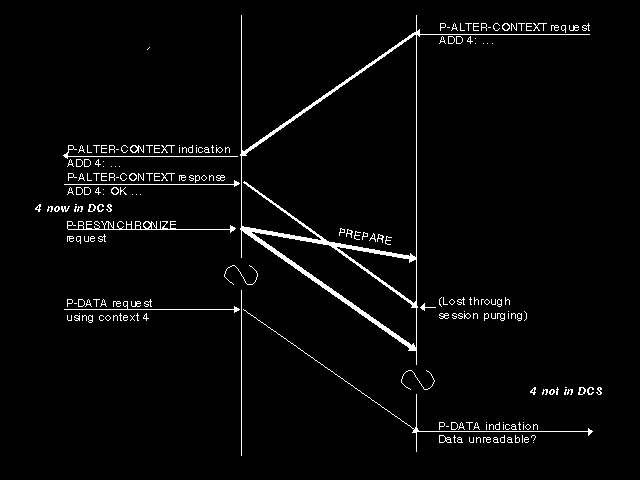{kind=link}
This raises an interesting philosophical question. If session resynchronization occurs, what should happen to the defined context set? If you believe strongly that "restart from a checkpoint" should be the (only) semantics an application can apply to a session resync, then it would be natural to want to have the defined context set restored to what it was at the time the checkpoint was taken, that is, the time the corresponding synchronization point was established. This is called context restoration.
Of course, if we are to do this, we need to make sure that the defined context set is indeed always in a consistent state at such a time. For sync points established by S-SYNC-MAJOR there is no problem - session dialogue separation prevents a P-ALTER-CONTEXT exchange spanning the dialogue boundary. In the case of S-SYNC-MINOR, however, dialogue separation is only achieved for a one-way flow, and the collision case shown in figure 7.6: Minor sync and alter context collision can in principle occur. Again, this can easily be resolved by forbidding the issue of a P-SYNC-MINOR if a P-ALTER-CONTEXT exchange is outstanding and we really want to make context restoration possible.
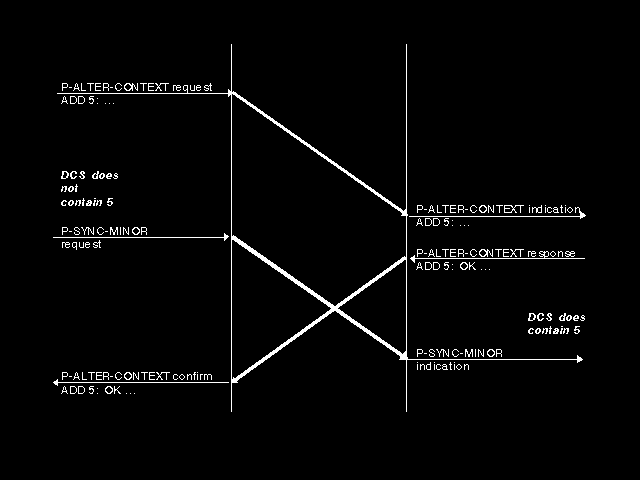{kind=link}
But do we? The reader will be aware that the checkpoint/back-up semantics is not built into the session layer. Resynchronization does nothing more than terminate dialogue one (disorderly) with a clean start to dialogue two, and with the sync point serial number variable set to an agreed value. It is for the application designer to associate checkpoint/back-up semantics with this, or not to do so. What then should the Presentation Layer assume?
There was considerable disagreement among Experts on what was appropriate. On the one hand, the checkpoint/back-up semantics is an obvious one for some applications to want, so providing context restoration as part of the Presentation Layer specifications looked attractive. Moreover, because, notionally, in the model, the knowledge of the transfer syntax used for a presentation context is encapsulated within the Presentation Layer, it is not possible within the terms of that model for an Application Layer checkpoint to record and later restore such data. This is more a debating point than a real problem: as was stated earlier, the total implementation is what matters, and checkpointing and restoring what is notionally Presentation Layer data is clearly possible. Nonetheless, this discussion adds strength to the view that context restoration should be provided.
Another problem is that clearly something has to be done. The collision problem shown in figure 7.5 is a very real one. We just cannot go on operating with different defined context sets.
This was one of the secondary (but important) issues at the upper layers meeting in Helsinki that resolved the Session Service user data problem. There gradually emerged a fairly clear consensus that many application designers did not want context restoration to be automatically applied, but rather wanted defined context sets to be unaffected by a resync in the non-collision cases (which will be the most common). So the rule mentioned earlier was invoked: "Your job is to produce standards: if you can't agree, make it optional". The context restoration functional unit was introduced. If not selected, then the defined context set would not be affected by resync (or by S-ACTIVITY-INTERRUPT and S-ACTIVITY-DISCARD) - provided the collision case can be resolved. If selected, then provided the resync was quoting a sync point number established during this presentation connection (remember the existence of resync SET), the defined context set would be reset to that which obtained when the sync point was established. The context restoration functional unit clearly only makes sense if the context management functional unit has been selected, since it is only in the latter case that the defined context set can change between the establishment of a sync point and a later resync, and such a restriction was included in the P-CONNECT negotiation.
That still leaves the problem of resolving the collision case. Discussion went on for about twelve months. There was consideration of a third exchange after the P-ALTER-CONTEXT response/confirm (see figure 7.7: Protecting by a third exchange) which would have the effect of disallowing a resync until it had been received. There was consideration of a new Session Service primitive exchange that would provide protection against a later resync using a PREPARE message, in precisely the same way that the second half of the major sync and resync exchanges obtained protection for the start of dialogue two. But in the end, the solution was again blindingly simple: if context restoration is not selected, then whenever an S-RESYNCHRONIZE request is issued, the user data contains not just the mapping of the presentation data values on the P-RESYNCHRONIZE request, but also a complete statement (giving the presentation context identifier, the abstract syntax identifier, and the transfer syntax identifier) of what the defined context set is at the end issuing the resynchronize request. Thus whilst the P-ALTER-CONTEXT exchange can still be disrupted, we still achieve a consistent defined context set at both ends following the resynchronize request/indication exchange. Of course, we have in the same way to carry this message on the S-ACTIVITY-INTERRUPT and S-ACTIVITY-DISCARD exchanges, but that poses no additional problems.
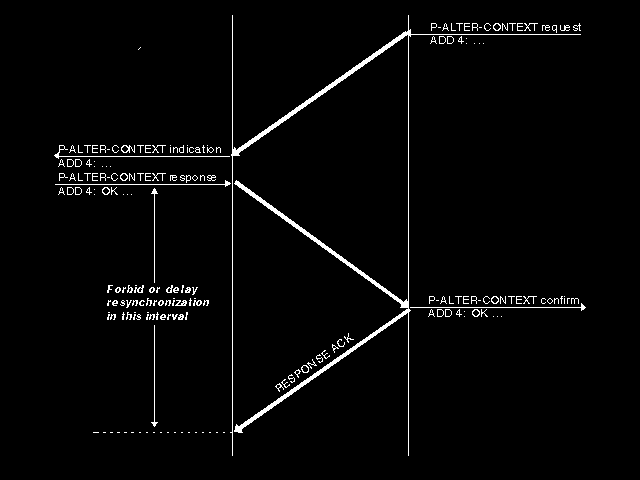{kind=link}
In fact, it did not prove possible to completely solve the collision problems if both the context restoration and the activity functional units are selected, and "data unreadable" situations can occur in this case. However, no application designer has so far (it is believed) chosen to use these options. Indeed, despite all the work that went into providing for it, no application designer for an international standard has chosen to use the context restoration functional unit at all!
The above discussion has hopefully served not only to identify to the reader the tools provided by the Presentation Layer that an application designer has available, but also to develop further awareness of the problems which can arise from the purging effect of the S-RESYNCHRONIZE exchange, and which may affect an application designer's own protocol.
7.5.4 And what about Teletex?
We have seen the pressures for Teletex compatibility in the Transport and Session Layers. What about the Presentation Layer?
The Presentation Layer Standards came somewhat later, and now the issue had changed. X.400 (1984) had been published, with the X.410 Recommendation containing all the interaction with the lower layers. This, as mentioned earlier, made direct reference to the issue and receipt of Session Layer services (in a way that was believed to produce Teletex compatibility in terms of the bits on the line.) Thus the pressure on the Presentation Layer was not described in terms of Teletex, but rather in terms of being able to specify X.400 (1988) in terms of the issue and receipt of P-service primitives again with no change to the bits on the line compared with X.400 (1984). This was quite a tall order and, if anything, was harder than the task that had faced Transport and Session. In the event it proved possible only by the lucky accident that ASN.1 had assigned (back in 1982) the same universal class tag value to both the SEQUENCE construction and to the SEQUENCE OF construction.
Two things had to be done to accommodate X.410. The first was to introduce the concept of a default presentation context determined by prior agreement. In the case of X.410, this of course meant the X.410 protocol and the ASN.1 Basic Encoding Rules! The second was to introduce a parameter into the P-CONNECT primitives called Mode Mode values "X.410-1984-mode" and "normal". The former value modified the behaviour of the presentation protocol (following the P-CONNECT exchange) to be effectively a null layer. Once again, the desired political objectives were achieved, and X.400 (1988) did indeed proudly boast that it was now a respectable application sitting on top of the Presentation Layer. The X.400 text did, however, have to consider the setting of the "Mode" parameter. How to get backwards compatibility and yet permit a movement into the future?
As frequently happens in such difficult areas, the CCITT Experts and the ISO Experts disagreed. The texts say how to run X.400 with the parameter set in both ways (such differing implementations, of course, not being able to interwork), but which to support (or both) is left as an implementation option.
7.6 Connectionless Presentation Services and Protocol and Related Issues
As with the other layers, the connectionless Presentation Service is very simple: just a P-UNITDATA request and indication. There is, however, some significant added value. The exchange carries a list of presentation data values which are treated in a very similar manner to the list on the P-CONNECT request/indication primitives. The message carries, for each presentation data value in the list, the abstract syntax identifier for the presentation data value, followed by a set of multiple encodings, each carrying a transfer syntax identifier.
This focusses attention on the problems of negotiation of an agreed transfer syntax when the communication is essentially a one-way flow. This problem does not just occur with connectionless communication. Consider an electronic mail (X.400) message carrying a spread-sheet or some form of image. The precise encoding of the spread-sheet data, or the image format to be used is a transfer syntax issue, and some negotiation could be desirable. But X.400 is both a relaying and a broadcasting application, and negotiation in a P-CONNECT is clearly not useful. Similarly, selection of a good transfer syntax for storing a file on a general-purpose file-server (which can perhaps in the general case only store the file but cannot transform from one transfer syntax representation to another, and where the file is to be retrieved later by multiple other systems) poses the same relay and broadcast problems. All these cases might benefit from the "multiple encodings" used for the P-CONNECT and P-UNITDATA primitives, although such an approach is not currently employed by either FTAM or X.400.
Another approach to negotiation in the relay and connectionless cases (but with less applicability where there is a broadcast element) is to have a potential recipient lodge, in some form of world-wide directory (such as that provided by X.500) the transfer syntaxes it supports for each abstract syntax that it supports, and to let the sender of the data select from this list. The use of X.500 is, however, not sufficiently mature yet (nor is the problem of negotiating transfer syntaxes yet serious enough) for these approaches to have been developed.