
4 World-wide connection
4.1 Introduction
In this Chapter we will discuss in somewhat more detail the most important piece of standardization in the whole of OSI - the Network Service Definition. First, let us review the concepts introduced in the architectural discussion. We are here concerned about
- Agreeing on an end-to-end functionality (the nature of carrier services) for data transmission over networks on a world-wide basis.
- Identifying the types of message exchange to be provided and the parameters of those messages.
- Defining a notation to support the linkage between Network Layer protocols claiming to provide support for this functionality (to arbitrary Transport Layer protocols) and Transport Layer protocols wishing to make use of this functionality (over arbitrary carrier protocols).
In the architectural discussion, we described the Network Service Definition as "the decking", summarising the Internal Organization of the Network Layer Standard by saying, "It doesn't matter what goes on down below. All that matters is the decking". At this point in the text, however, we have to explain to the reader that there are two styles of "decking" that are Standardised for the ship:
Her Majesty's Ship the Network Carrier One has a flat deck with scrubbed bare boards. It needs little beneath it, and travels very fast. By contrast, Her Majesty's Ship the Network Carrier Two has very ornate decking, beautifully crafted, with mahogany filigree inlays, and sails beautifully across the roughest seas.
The reader will ask why it was necessary to standardise two types of decking. We address this in the next section, and consider the details of the interchanges (the Network Service Definition), and addressing and routing issues in the remaining discussions of this chapter.
4.2 End-to-end functionality
Following the description of the functions of traditional single-link protocols, we recognise the need to provide (at least on an end-to-end basis):
- Framing of bits into messages.
- Error detection for corrupted messages.
- Error correction by retransmission of messages.
- Flow control to prevent over-run.
We have protocol standards in place (HDLC) which can provide all these functions over a single link, and as our first attempt at defining the Network Service, we will assume we simply put end-to-end a set of links to provide an end-to-end service with these properties. An alternative approach is introduced later, where we do not exercise all these functions on a per-link basis, but rather defer some for end-to-end (only) provision.
Of course, there are some further features that we need to introduce as part of the Network Layer standardization providing a world-wide service that go beyond what is needed in the link layer. These are
- Multiplexing: We need to recognise that at least our internal links between nodes will have to carry (simultaneously) communications relating to the transmissions of many pairs of end-systems, not just one, and that it is probably desirable to provide flow control on an individual channel of communication, so that a "stop-sending" message from one end-system does not cause a complete internal link to be blocked for transmissions which are not related to the one for which the "stop-sending" was issued.
- Addressing and routing: We need to solve the problem of how an internal node can determine which outgoing link to send a message on, and to recognise that multiple paths may be possible between different end-systems, with different overall properties.
If we are to handle the multiplexing and flow-control questions, then we are forced into recognising the concept of sequential messages forming part of some connection which threads its way through the network between a pair of end-systems (each end-system pair potentially having more than one connection between them, each one being treated independently). We also have to recognise that "stop-sending" messages may need to be generated by internal nodes, not just by end-systems, if over-run is to be prevented when (for example) one particular output link from the node is getting overloaded. Such messages need to be applied to only those connections on other links that are "feeding" the overloaded outgoing link: it is not satisfactory to simply choke off all communication on all other links.
Thus we are led to the concept of logical channel identifiers that are known to (remembered by) internal nodes, with this information stored when a logical connection is first established, and forgotten when the connection is released. Flow control messages can now be designed which contain a logical channel number, and hence affect only data on that single logical channel.
We get a small bonus from this arrangement. If a node detects that the link accessed by one of its ports has failed (because the link-layer protocol is not being honored), then it can use its knowledge of what connections are running through that link to send messages back saying the connection has broken. Equally, if the buffer allocation mechanism for a node occasionally fails, causing it to have to discard some data messages for some particular connection (but the connection is still in place), it again becomes possible to signal this in both directions. We talk about a network-generated disconnect and a network-generated reset in these two cases.
One final point, and we are almost there! Once we provide a flow-control mechanism, we really need to provide for an end-system some means of signalling (in violation of the flow control) "Look, we are blocked, do something about it." This is commonly called an interrupt message, or in OSI terms, the transmission of expedited data - "expedited" because it can overtake normal data if flow-control (perhaps transiently) is blocking the normal data.
So ... we have a variety of messages which are understood by internal nodes and end-systems (set up a connection, disconnect, reset, expedited data, normal data), and a pretty complicated protocol to be implemented by those systems, on top of the already pretty complicated full-function link-layer protocols they are implementing. What has been described and developed above is in broad terms the X.25 protocol which is both the de jure and the de facto protocol for provision of public data communication services by PTTs, and is also widely used in private networks.
But ... can we do any better than this? Is this really the best way of putting together a set of links to provide an end-to-end service? (See figure 4.1: From links to networks.) (PLBO=potential loss by overrun, PLBE=potential loss by error, ECBR=error correction by retransmission.)
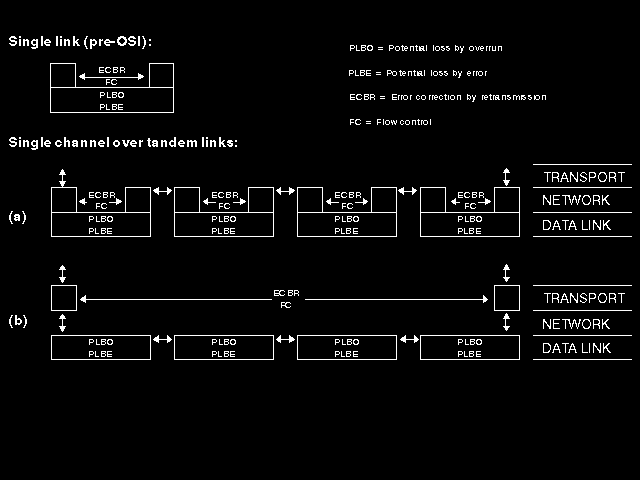{kind=link}
The above treatment seemed to follow logically from chaining together full-function links. ((a) in figure 4.1) But maybe some of the things done in the link level protocol for a single link between a pair of end-systems would be better done on an end-to-end basis, not on each link, when we chain links together through network nodes to provide a world-wide network service interconnection? Suppose, in particular, that we take only the essential link layer functions of framing and error detection (with resulting discard), and leave all question of flow control and error correction by retransmission as matters to be solved by exchanges between the end-systems involved, with internal nodes having no knowledge of such exchanges ((b) in figure 4.1). What happens then?
We no longer need to introduce the concept of logical channels as far as the network nodes are concerned (in the network layer). These, together with any associated retransmissions and flow control can be part of a higher layer specification (the Transport Layer). As far as the network layer is concerned, we have only one message, the data message. We ensure that each data message contains the address of its destination, solve the routing problem (see later), and treat each message independently. We have no concept of a "connection": we have designed a connectionless communication protocol. (The term "datagram service" has in the past been used to describe this form of operation, but the term is not used in OSI.)
What then does this connectionless mode (to use the OSI terms) give us compared with the X.25 connection-oriented mode? First and foremost, it gives us a very simple set of protocols to be operated in relation to the main data transfer by network nodes. Such nodes can therefore be fast and cheap (in comparison to X.25 switches). Secondly, the end-to-end service results in the following features occurring on a fairly frequent basis that (probably) have to be addressed by a protocol between the end-systems if applications are to run successfully:
- Occasional loss of messages due to corruption on one of the links in the path;
- Occasional loss of messages due to congestion in a network node (if you can't say "stop-sending" when your buffers are getting full, your only other option is to discard any other incoming material), dependent on the amount of traffic being generated by other end-systems.
- Occasional delivery of messages out of sequence because the "best" route changed between the transmission of the two messages.
- Retransmission (if done by end-system to end-system exchanges) following loss or corruption involves a delay corresponding to a full network-wide round trip time, rather than to a single-link round-trip time.
- No notification to a sender that the communication has failed.
In fact, on the latter point, we can relatively cheaply provide some sort of facility in this area. We probably want to carry the address of the sender in every message anyway (so that the end-system knows where the message has come from) and if we make this visible to the network nodes, then we can arrange to send a message back to the sender if a network node discards messages for some reason or other. Note, however, that in contrast to the network-generated reset and disconnect messages in the "connection-oriented" approach, there is no guarantee that these messages will actually get back - they also may get discarded through corruption or congestion.
So ... where are we now? We recognise two different ways of approaching a world-wide network service. We can either take the connection-oriented approach of a "reliable" service over each link, but with quite complex protocols for network nodes, or the connectionless approach of a very simple network protocol, but with more work to be done by end-system to end-system exchanges that are transparent to network nodes. Which is best? If you are a PTT, trying to make money from a public service to customers, I wonder which you would choose? How do you charge a customer if you throw away five per cent of everything the customer gives you? Still worse, the percentage you throw away will be dependent on what other customers are doing! Maximising the size of your own market sector clearly leads to provision of the "reliable" (but perhaps more expensive) service. In practice, the connection mode of operation was adopted by CCITT in the X.25 protocol. It was the only mode of operation in the first Reference Model Standard, but the connectionless mode of operation was added to both the ISO and the CCITT text as an addendum. Why? (See the following text.)
Whilst focus on the provision of a public network service might lead to a favouring of the connection-oriented approach, if computer vendors are to market networking products using their own switches (connected by leased lines), they are likely to favour fast cheap switches (sorting out any resulting mess in their end-systems) and hence the connectionless approach. In practice a number of computer vendors adopted the connectionless approach, and this is the approach also used in the Internet (the TCP/IP community), discussed earlier, where IP is the (connectionless) network protocol known by nodes and carrying data and global addresses, and TCP is the (connection-oriented) error correction, reordering, flow-control-providing protocol run by end-systems.
Quite clearly then, both approaches are viable ways of providing a network service, and there was a substantial lobby for the standardization of both approaches. As an aside, there are clearly some possible half-way houses, such as end-to-end transmissions in which loss of order does not occur, or in which reliable link protocols (error correction by retransmission) are used but loss due to congestion remains possible. Current interest in frame relaying and on the most appropriate network service to provide using very high bandwith (a few hundred gigabit per second) optic fibre networks is focusing on intermediate types of service that may in the future become sufficiently important to be added as recognised types of OSI Network Service. For the present, however, there are just the two extreme services standardised, with no suggestion of producing standards for any service that is part way between the two.
I have so far described the favouring of the two-approaches as a PTT versus computer-vendor divide. This is not wholly true. Some computer vendor networks are connection-oriented in nature. It is also the case that there was in the 1980s something of an Atlantic divide, particularly between the academic communities, with the USA firmly favouring (with the large Internet investment) the connectionless approach, and the UK (and to some extent other countries in Europe) building large private X.25 networks. (This divide broke down in the 1990s, with a growth in the use of TCP/IP - connectionless - private networks in Europe.)
Which approach is best? There are experts who will argue very cogently on behalf of both approaches. There are uncontested advantages for each approach, as well as contested points (such as which approach degrades more gracefully if a lot of nodes and links fail?). Some further discussion of the pros and cons of (a) and (b) of figure 4.1 is presented in chapter 5.
Which approach will stand the test of time? Again it is hard to express an opinion. PTTs will be slow to abandon X.25 (and hence the connection-oriented approach), but there are some features of internal ISDN operation that are connectionless in nature, and the overall impact of ISDN, particularly broad-band ISDN (B-ISDN) is yet to be determined. Equally, it is clear that the Internet community and a number of computer vendors see any migration to OSI as being to the "connectionless" Standards, and once such migration is complete the connectionless approach is likely to have a very long life. It looks fairly likely that we will be left with both approaches for some time, with any move to a single approach being dependent on the transition to very high band-width real-time networks.
Is it a good or a bad thing to have the two approaches standardised? At one level, it was essential. If OSI had contained in the 1980s only the connectionless approach, it would never have been accepted by the PTTs. Equally, if it had only the connection-oriented approach, it would never have been accepted by some computer vendors, or by the Internet community, and any move from TCP/IP to standardised protocols would be even more difficult than it is now.
What of interworking? There are a few points to make. First and foremost, it is always possible to treat an X.25 connection (or any other connection, such as an ISDN connection) simply as a link between internal network nodes, and to use that link to form part of a connectionless network service. (This is sometimes called "tunnelling through" X.25 - an approach frequently used for LAN to LAN interconnection). If the X.25 link actually provides a direct connection between the two end-systems, then the frequency of loss over it will be very small, but that does not prevent it being used as if the frequency was high! Secondly, two end-systems, one of which implements only the connectionless network service over an X.25 interface, and the other of which implements only the connection-oriented network service over an X.25 interface will not interwork over a direct X.25 connection between them.
If one accepts that both connection-oriented and connectionless approaches will be around for a long time, it would seem desirable for the majority of computer vendors to implement both the connection-oriented set of protocols and the connectionless set of protocols over both their X.25 interface and their Ethernet interface (for example). Moreover, it would be desirable for network nodes with Ethernet or leased line or X.25 interfaces to be capable of routing both connectionless and connection-oriented traffic over all their interfaces. There are signs that this (particularly the latter) is beginning to happen, but once such a situation is achieved (making both connection-oriented and connectionless communication possible between most pairs of end-system), the way a decision will be taken in an instance of communication to use one or the other mode of communication is unclear. Certainly there is nothing in the standards today to permit any form of negotiation of which to use, nor is there any real consensus on which is best in various cases, save that:
- Where the interconnection between a pair of end-systems is formed by a single PTT-provided X.25 connection, it is probably more efficient and less expensive for the end-systems to run in the connection-oriented mode.
- Where an X.25 path is used between internal nodes to connect two Ethernets, and there are multiple communications running between different end-systems on the two Ethernets, it is probably more efficient and less expensive for the end-systems to run in the connectionless mode (because that enables use of a single X.25 connection for all the communications, whilst the connection-oriented approach in this scenario needs a separate X.25 connection for each end-system communication).
In the absence of most vendors implementing both approaches, there is a real potential for the world of conforming OSI systems to divide into two non-communicating parts - those containing implementations of the connection-oriented protocols and those containing implementations of the connectionless protocols. To address this problem, an ISO Technical Report (TR10172, "Network/Transport Interworking Specification") has been produced describing the operation of an Interworking Unit that relays at the top of the Transport Layer to provide interworking between these two worlds. This is strictly in violation of the OSI architecture, as the Transport Layer protocols are supposed to be for "QOS (Quality of Service) improvement" directly between the end-systems and have no role in the provision of end-to-end connectivity. It also suffers from the practical disadvantage that the QOS (undetected error rate, or frequency of signalled errors - resets or disconnects) actually seen by the application is not dependent solely on the two end-systems, but also depends on the quality of the Interworking Unit. For these reasons, the Technical Report has a Health Warning saying, roughly (but in more guarded language):
This Technical Report was produced by the group defining OSI Standards. It is not, however, an OSI Standard, and never will be an OSI Standard, but it is an agreed specification that may be useful under some circumstances.
The extent to which such an Interworking Unit gets actually deployed in the field (if at all) remains to be determined.
4.3 The OSI Network Service Definition
This text is largely a summary of what has gone before. Formally, the OSI Network Service is a single service that contains both connectionless and connection-oriented exchanges.
The connectionless exchanges at the service level are particularly simple - a single message carrying up to (just under) 64K bytes of data. This is reflected in the service as the N-UNITDATA request and indication primitives. The service definition also includes a queue model that gives (in an abstract way) precision to the fact that there is no flow control, may be loss of messages, and may be re-ordering. As an aside, the Connectionless-mode Network Protocol (CLNP), is actually not as simple as the above discussion implied, as it needs to address the problem of limited message sizes on various carrier links (not necessarily known to the end-systems involved), and hence the need for network nodes to fragment the messages and for reconstruction at the receiving end. This is, however, buried in the protocol, and is not visible in the service definition. The 64K limit is, however, present in the service, and reflects limitations in the protocol on the number of bytes used for various length fields. It should also be noted that it is not expected that connectionless messages will normally be anywhere near the 64K limit, due to the point made earlier that the probability of loss of the whole message depends on its total size (there is no mechanism for retransmitting fragments, so if one fragment is lost by corruption or congestion, the whole message is lost).
The connection-oriented exchange involves many more service primitives. Again there is a queue model that is used to abstractly describe the existence of flow control, the in-order delivery, the possible bypassing of normal data by expedited data, and the potentially destructive nature of resets and disconnects in relation to data sent but not yet delivered. The service primitives (with corresponding message types) are:
- The N-CONNECT request, indication, response and confirm to set up a connection (and which can also carry up to 128 octets of user data in each direction).
- The N-DISCONNECT request and indication (the indication resulting from either an N-DISCONNECT request or from a network-generated disconnect), again carrying up to 128 octets of user data.
- The N-DATA request and indication carrying an unlimited length of user data (in this connection-oriented case, the unlimited length is fully usable, because retransmission of fragments occurs across each link in the communication). For those familiar with X.25, the fragmentation corresponds to the use of the X.25 more bit, with the service primitive corresponding to the transmission or receipt of a complete X.25 M-bit sequence.
- The N-RESET request and indication (carrying 128 octets of user data). This is used to signal loss of N-DATA primitives, but without loss of the connection. Although the request primitive is formally defined, it is expected that resets in OSI use will normally arise only from network nodes.
- The N-EXPEDITED request and indication (carrying 32 octets of user data). This primitive by-passes flow control.
- An N-DATA-ACK request and indication (no parameters).
Of the above, only the N-DATA-ACK may seem curious to the reader. Acknowledgements are normally internal matters to the protocol, operating on a link-by-link basis, so why do we need such a service primitive? When X.25 was first implemented, some PTTs produced networks where an acknowledgement for receipt of the last fragment of a complete M-bit sequence was only given to a sending system when the message had been acknowledged by the receiving end-system (end-to-end significance of acknowledgements), whilst others gave an acknowledgement when the last fragment had been received by the first network node. (The first X.25 Recommendation did not make it clear which was intended.) The main difference for the user is that in the former case a later disconnect request could not overtake and destroy the acknowledged data, whilst in the latter case it could. In the 1980 revision of X.25, the situation was clarified by the introduction of the so-called D-bit (D for delivery) by which a sender could request (on each message) whether end-to-end acknowledgement was needed or not. The N-DATA-ACK (and a corresponding parameter on N-DATA to request end-to-end acknowledgement) is a formalization and abstraction of this end-to-end acknowledgement provision in the X.25 service. The way this feature is used in the transport layer is discussed in the next chapter.
It is beyond the scope of this text to give a more detailed treatment of the parameters of these primitives, but there are no new concepts involved, and the interested reader should now be well able to read the actual Standard.
You will no doubt have noted from the above discussion a very close relationship between the de facto service provided by X.25 and the formally-defined (connection-oriented) OSI Network Service. The match is actually extremely close, but not total. (Skip to the end of this discussion if you are not familiar with X.25). In particular, the X.25 Q-bit does not appear in the OSI Network Service. The main (only, in international specifications) use of this bit is in the X.29 protocol supporting terminal login over X.25 to remote systems. This protocol is an application protocol, and hence in the OSI architecture should not be running directly over X.25 anyway, so in principle the loss is not too great. Moreover, the OSI Network Service is in practice provided over Ethernet (and other LANs), leased lines and ISDN by the use of the X.25 protocol, so the Q-bit is in practice if not in theory available end-to-end provided only that it is correctly mapped by actual relay systems.
As far as the provision of the OSI Network Service is concerned, it has already been stated that X.25 (1984) does indeed fully support the (connection-oriented part of the) service. In the 1980 version, there were problems with support of N-EXPEDITED (which carries 32 octets of user data) by the X.25 INTERRUPT packet (which could carry only eight octets of data). There was also a problem that in some cases the X.25 DISCONNECT packet did not make provision for carrying the 128 octets of user data specified in all circumstances for N-DISCONNECT. The major impact of these problems was that the OSI Network Service Definition introduced an option into the definition. The availability of N-EXPEDITED was made optional and subject to negotiation. This had a somewhat unfortunate knock-on effect when we get to the Transport Layer, and indeed on up to the Application Layer, as we shall see later.
4.4 Addressing and routing issues
There has probably been more written on addressing and routing in traditional Data Communications texts than on any other single subject. It is not the purpose of this text to add to that coverage, and the reader who is interested in a more theoretical treatment of the issues and options should consult those other texts.
There are many aspects of naming and addressing, some of which go beyond the network layer, but are treated in this discussion because an understanding of them is needed to set the scene.
There are two levels of naming in OSI (much as there is in TCP/IP). At the top-level, there is a relatively user-friendly, organization-structure-related naming scheme for end-systems and the applications running on them. These names are called system-titles and application-entity-titles. (For those that know TCP/IP, they correspond closely to the domain names of the Internet). This top-level of naming is converted by local look-up tables or by a directory query into a 20-octet Network Service Access Point (NSAP) Address (which globally identifies the associated end-system, be it attached to an X.25 network, an ISDN connection, an Ethernet, or whatever) together with a set of selectors (one for the Transport Layer, one for the Session Layer, and one for the Presentation Layer) which provide fan-out to applications within an end-system (see figure 4.2: Addressing fan-out). In TCP/IP, by contrast, there is a 32-bit Internet Address (carried by IP) corresponding to the 20-octet NSAP Address, and a single fan-out parameter, the port number carried by TCP (see figure 4.3: TCP/IP address fan-out). Provision for three selectors in OSI (of which typically all but one will be null) allows for various implementation structures of the upper layer code in actual systems and is discussed further in chapter 9.
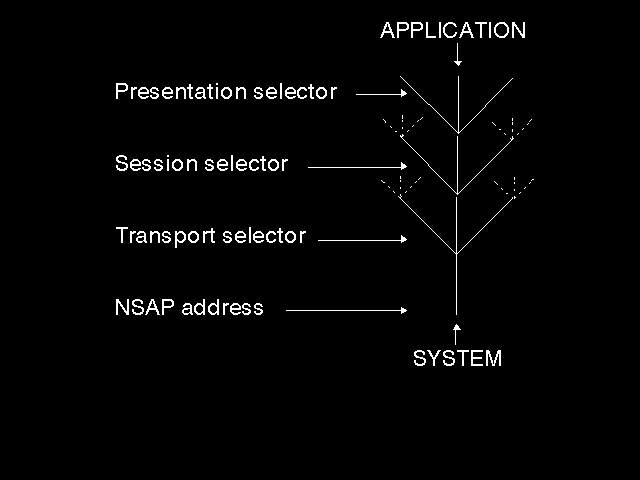{kind=link}
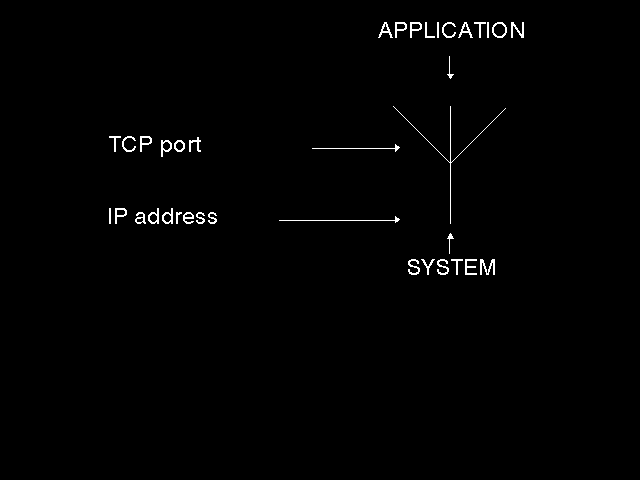{kind=link}
The OSI Network Service definition requires that supporting protocols carry the NSAP Addresses of the called and calling systems end-to-end. This is essential to support the use of these addresses by relay systems in progressing the total network connection. It is again a failing of X.25 (1980) that it has no provision for carrying such addresses, and hence cannot be used for anything other than a single-X.25-hop direct connection between a pair of end-systems. This is corrected in X.25 (1984).
The allocation of IP addresses in TCP/IP is a very centralised matter. By contrast, OSI NSAP addresses allow an address for a system to be constructed out of a whole variety of other globally unambiguous information. This is partly why the NSAP address space is so large. In particular, the address can be formed using a combination of an X.25 and an Ethernet address, or using a telephone number, or using an ISDN number, or using a number obtained by an existing Registration Authority that allocates International Code Designators (ICDs) to international organizations, or using an allocation from an ISO/IEC National Body. Note, however, that the sole purpose of the NSAP address (like the TCP/IP IP address, but unlike X.25 addresses) is to provide an unambiguous identification - the internal structure is irrelevant. The fact that it might be constructed using some specific telephone number, or some specific X.25 address, carries no implication that the corresponding end-system can be accessed, either directly or indirectly, by a call to the corresponding telephone socket or X.25 port.
So much for addressing - the provision of world-wide unambiguous names for end-systems. Now what about routing? How do network nodes learn where to send connectionless packets or connection requests that they receive? In the case of X.25 addressing, address space is allocated initially to a PTT or RPOA, and is then typically allocated in accordance with the topology of the X.25 network run by that PTT or RPOA. In particular, it is necessary to change people's addresses if the network configuration is changed by the splitting of one switch into two (for example). Routing tables in these circumstances can be based on the hierarchical structure of the address, and are typically manually configured and fairly static.
This feature of X.25 addresses has led some people concerned with connection-oriented communication to tend (incorrectly) to ignore routing problems. Even where an end-to-end public X.25 connection is possible, this is not necessarily the optimum route between a pair of end-systems if bandwidth and cost are taken into account and if private network overlays are present. Most of the running in producing Standards for protocols to support the distribution of routing information has come from those mainly interested in connectionless communication, despite the fact that both communities have precisely the same requirement for the distribution of routing information related to NSAP addresses. Fortunately, the emergence in the early 1990s of new products that were primarily developed to support connectionless traffic (and hence the routing protocols supporting that traffic) but which were also capable of routing connection-oriented traffic (using the same routing tables) largely eliminated the problem.
So how does routing work in OSI? It is very similar to the latest routing approaches in TCP/IP, recognising three levels of division of the world for the purposes of routing activity. The highest level comprises a complete routing domain, and would normally correspond to a complete organization. (Geographically of course, routing domains are really overlapping planes. They are rarely disjoint, and permitted cross-connections between organizations are links between these overlapping planes - see figure 4.4: Overlapping planes). The next level allows the organization to have what is essentially a backbone of level 2 intermediate systems serving a number of areas consisting of level 1 intermediate systems. Within the lowest level (a level 1 area), every intermediate system (network node) maintains a complete picture of all end-systems and intermediate systems and the available links between them (each link having a set of "costs" associated with it), and calculates "least-cost" routes to each system in the domain. "Cost" can be based on money charges (the expense metric), on bandwidth (the default metric), on expected delay (the delay metric), or on the probability of undetected errors (the error metric), resulting in four potentially different routes to each destination in the level 1 area (one for each metric). The actual route chosen depends on flags in the data messages being routed (and reflected as QOS parameters in the Network Service) that indicate trade-offs requested for this connectionless message or connection.
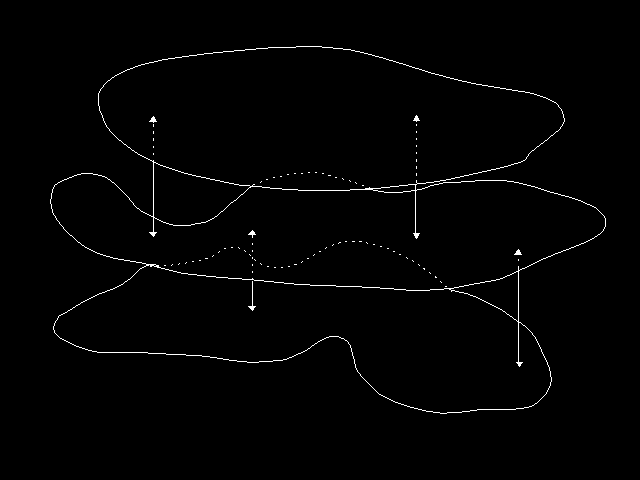{kind=link}
The most common algorithm for calculating least-cost routes is based on work done by Dijkstra, and is well-described in many text books. The actual protocol (ISO 10589) involves each intermediate system noting the state of each of its links (including the metrics for that link), and flooding that information throughout the entire level 1 area. Routing between these lowest level domains does not involve complete flooding, and routing at the highest level (between independent organizations who may not wish to make their internal structure or connections to other organizations known generally) was still under development in the early 1990s, and is likely to involve manual configuration to at least some extent.
Within the lowest level of domain (where the traffic will be greatest) there will be optimal routing. Between independent organizations, however, routing will, in general, and of necessity, be sub-optimal. Thus two routers connected to the same local PTT X.25 exchange in Europe, but owned by two different international organizations, may not know about (or be allowed to use) the direct route between them, but will instead know about and use a route half-way-round the world and back, via their head offices in the USA, and passing through the local PTT exchange going out and coming back.
4.5 Network layer protocols
There are broadly four categories of protocol that have been developed for the network layer (see figure 4.5: Categories of network layer specification). We have met them all implicitly in the earlier text, and this short discussion merely draws the earlier work together.
{kind=link}
First, there is the protocol which forms the main back-bone for connection-oriented services, either over a LAN, over ISDN, or over a PTT network. This is called the X.25 Packet Layer Protocol, reflecting its origins in the X.25 Recommendation. In fact, it is a slight generalization of the CCITT X.25 Recommendation, reflecting the fact that for OSI use (particularly over LANs, leased lines, and ISDN) we have two identical implementations (DTEs in X.25 terminology) directly communicating, whereas in a PTT's network, the standardised communication is always between a DTE and a DCE (a network node) which are configured to know their role, and implement slightly different rules of procedure. (Internal DCE to DCE protocols are not the subject of CCITT Recommendation, and are a matter for individual PTTs and/or implementors of X.25 switches. This is why X.25 is sometimes described as being only an interface protocol, not a network protocol.)
Similarly, there is the protocol that forms the main back-bone for connectionless services. This protocol (Connectionless Network Protocol - CLNP) is very strongly-related to the IP protocol of TCP/IP, with almost identical functions and fields in messages, although it is not quite bit-for-bit compatible. There are two main differences. The first is that the addresses being carried are 20 octet NSAP addresses, not 32 bit TCP/IP addresses. The second is that the protocol for sending "we can't deliver it" messages back to a sender is a separate protocol in TCP/IP (ICMP - Internet Control Message Protocol), but is a part of CLNP in OSI. Other differences are minor, but do exist.
The third group of specifications provide the convergence from existing real networks to the OSI Network Service. They generally reference one or other of the above specifications, saying how the network layer protocol is to be carried over the actual real network.
And finally, we have a collection of specifications related to the routing problem, starting with a Technical Report introducing the concept of Inter-domain Routing (within a single organization) and Intra-domain Routing (between independent organizations), and extending to protocols for communication between intermediate systems (generally of the "flooding" variety) and communication between end-systems and intermediate systems to make themselves known. Further details on these protocols is beyond the scope of this text.
4.6 New approaches
In the late 1980's, stability of the network service was largely assumed (and hence of the middle layer protocols and services - Transport, Session, and Presentation - which were defined to be independent of network technology and applications). In the early 1990's, however, new approaches began to be developed which introduced some instability into these areas.
The history of networking has been one of questioning the obvious and developing new approaches. Thus in the early 1980s it was apparent that one could signal down links at speeds far in excess of the ability of cheaply-available computers at that time to switch the traffic between different links. How then to build high-speed (megabit per second) networks switching traffic between different links? The answer is blindingly obvious once presented: "Don't switch!" - send to everybody and let the destination select traffic destined for it. This was one of the key ideas which allowed the development of local area networks: cabling systems in which traffic floods to all stations with no switching. Of course, there remained the problem of determining who had control of the medium (was allowed to transmit) at any point in time, and a variety of contention and token-controlled mechanisms were developed to provide "fair" access to the medium by each station in a controlled and shared manner. In most (but not all) cases these mechanisms were distributed, with the only intelligence in the network being in the attached stations. None of this, however, really impacted the Network Service. Ethernet and Token Ring Local Area Networks were just another hop in the provision of either a connection-oriented or a connectionless Network Service.
The developments in the early 1990's, however, were more significant. The issue being addressed in this case was how to cope with congestion and potential overrun within the network. Traditionally we have seen two approaches to the problem of "What happens if a network node is receiving traffic on one or more of its links faster than it can dispose of it on some other link?" (A similar problem exists if an end-system cannot accept traffic as fast as the network is trying to deliver it). The first approach to the congestion problem introduces the relatively complex X.25-like protocols to say "stop" and "go on", and produces the connection-oriented Network Service. The alternative approach simply discards traffic when congestion occurs, producing the connectionless Network Service. At first sight, these are the only two possibilities if a node gets overloaded.
There is, however, another option. Why not agree the bandwidth that is to be provided, using some negotiation at the start of a connection, and then have all parties support (and keep within) that bandwidth? There are still quite complex protocols needed, but they can now operate once at set-up time and do not affect the speed of handling the main traffic. We thus get a "light-weight" but connection-oriented-like (no discard) service. Moreover, the error rate on signalling systems using optic fibre has dropped to about 1 in ten to the power 14, even for extremely high transmission speeds, compared with about 1 in ten to the power 7 for old-fashioned signalling on copper wires, so loss due to detected errors becomes less of a feature.
There is one other important advantage of this so-called "managed bandwidth" approach: because queues are no longer needed to smooth out statistical variations in traffic, much better network delay characteristics and delay jitter (variation in delay) can be achieved, making it possible to handle real-time voice and video over such networks in an effective manner. The disadvantage, however, is that it assumes a steady flow of data and is clearly inappropriate for traffic that is inherently bursty. Queues, however, are not the only source of delay. If a packet is to be stored (for error detection or routing analysis) before being forwarded, there is inherently a delay introduced by the node equal to the time taken to transmit the packet, and hence proportional to the packet size. Equally, whatever multiplexing or medium access control mechanism is provided, the unit of multiplexing will be the packet, and hence the delay before it will be possible to send material related to some channel of communication is proportional to the packet size in use. Both these issues give rise to a need to work with small packets (called cells - 48 bits long) if low-delay characteristics are needed.
Another important development was the approaches to compression of video data that emerged in the 1990s. One important technique requires a base transmission of information (relatively low band-width) whose correct transmission needs to be guaranteed, and which is sufficient to produce a "reasonable" picture, whilst additional transmissions are needed to produce a good picture, but their loss is not disastrous. With this approach, the network needs to guarantee the base transmissions (vital, high priority), but can afford to provide only a probabilistic service for the rest (enhanced picture, low priority). Discard (due to occasional milli-second congestion) of the low priority data will show itself only as a temporary degradation of picture quality and can be accepted (it may not even be noticed by the human visual system). Traffic with these sorts of characteristics clearly opens up a number of additional options for network design and bandwidth management.
There are a number of approaches emerging in support of these broad concepts, expected to culminate in the late 1990s in a wide availability of a "broad-band" wide-area network service giving speeds up to a few gigabits per second, and potentially rising to a few terra (ten to the power 12) bits per second, and with very good delay characteristics. Interested readers should investigate books and papers on "Broadband Integrated Services Digital Networks" (B-ISDN), on "Synchronous Digital Hierarchy" (SDH), on "Cell and frame relay", and on "Asynchronous Transfer Mode" (ATM). Such topics go beyond the scope of this book, but their impact on OSI in the late 1990's is likely to be important.
There was formal recognition in ISO during 1991 that these new technologies would require at least a refinement, and perhaps a more substantial reworking, of the OSI Network Service, and a consequent extension of the services and protocols of the Transport Layer (which is designed to improve the "quality" of the end-to-end Network Service). This formal recognition took the form of the establishment of New Work Items covering these layers to develop appropriate standards to meet the needs of high-bandwidth low delay networks and the applications that they made possible.
At the time of writing this book (1995) the precise direction of these new or extended Standards is unclear, and will be ignored in the rest of this text. It is, however, clear that the old arguments between proponents of the connectionless approach and the connection-oriented approach to provision of an end-to-end connection are likely to be overtaken by approaches based on ATM-based communication systems. The view of the Encyclopedia Galactica - 20085 version are given in figure 4.6: Encyclopedia Galactica, p21076.
{kind=link}