
10 Real applications - at last!
10.1 Message Handling Systems
The X.400 series of Recommendations (also ISO/IEC 10021) is a large and complex piece of work. The collected set of ASN.1 definitions stretches to some 5,000 lines. There are a number of separate protocols within the suite. The basic provision for the exchange between Message Handling Systems (electronic mail systems) of electronic mail in a Standard form, but these X.400 "messages" can be not only messages from a human to another human (so-called interpersonal messages), but can also be formatted messages from one computer to another to support exchange of trade-related messages (generally called electronic data interchange or EDI). Even for the interpersonal messaging system (IPMS), the messages go rather beyond old-fashioned electronic mail (which was in the 1980s and for much of the 1990s confined to ASCII text), being capable of carrying a very wide variety of so-called body parts, paving the way for multi-media messages. There are complete books on X.400 alone, and we shall be covering here only aspects that are of general architectural interest.
The model contains a User Agent (UA) (think of it as an implementation on a personal computer or workstation) that prepares a piece of mail for sending. The mail is an ASN.1 datatype which defines the form of header fields corresponding roughly to the letter heading on a normal letter, but also including (optionally) things like references to other letters that this one obsoletes, expiry dates, and so on. This so-called inter-personal message contains holes that can carry one or more Body Parts. In the earliest version, a small number of Body Parts of different types were hard-wired into the Standard, but with the maturing of the ASN.1 Object Identifier concept, a so-called Extended Body Part can be defined (with an ASN.1 macro in the late 1980s). The macro collects an object identifier and an ASN.1 datatype, but these holes are really presentation data value holes, capable of holding spreadsheets or wordprocessor files, as has been discussed earlier, and the definition of Extended Body Parts would actually have been better cast as the definition of an abstract and transfer syntax for such objects. The set of header fields in the IPMS were again hard-wired in the original Standard, but later became ASN.1 datatype holes, using EXTERNAL and a macro to define new object identifiers and data types to support additional headers.
Early in 1992 implementations of User Agents were beginning to appear, but there was still a lack of international agreement on object identifiers for Extended Body Parts that were vendor specific, particularly image formats that were de facto standards, spreadsheets from popular packages, and common word processing formats. One would expect such object identifiers to be allocated by the third-party vendor of these image, spreadsheet, or word processing packages, and distributed with the documentation of those packages, but at the start of the 1990s this had not yet begun to happen.
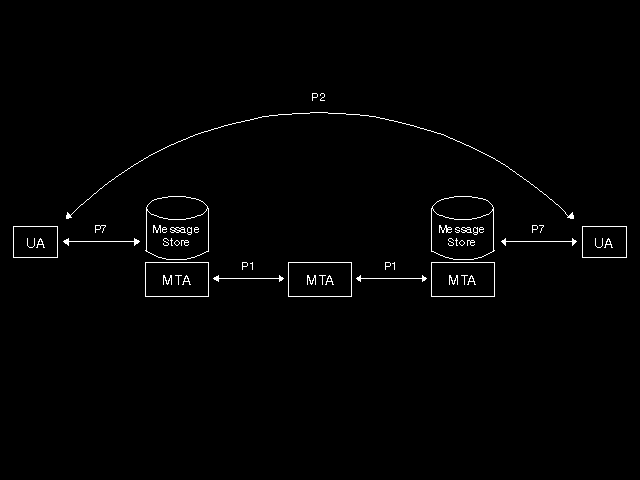
Once the Inter-Personal Message (IPM) has been constructed (with any necessary body parts), it needs to be submitted to a Message Transfer Agent (MTA) for delivery to a remote MTA. MTAs are simple relay systems that use the so-called P1 protocol to transfer mail between them. The P1 protocol involves the definition (as an ASN.1 datatype) of fields that correspond to envelope information in normal mail (although again with a great deal more richness and power). It is only the fields of the P1 protocol that are used by MTA implementations for relaying between MTAs to transfer the mail to a destination MTA. The relaying of these data structures is a simple and direct use of RTSE (RTSE was originally developed for precisely this purpose). This P1 datatstructure has one major "hole" which carries the contents of the message. In the original work the contents was either an interpersonal message, or various notifications of receipt or non-receipt coming back after a message had reached its destination. (The envelope itself contained provision for notification of delivery or non-delivery to the intended destination.) In 1990 the role of X.400 was considerably extended with provision to carry in this hole not just Inter-Personal Messages intended for human beings, but also EDIFACT, X.12 and TDI (see earlier discussion of EDIFACT) messages intended to be generated and processed by computers. Thus the electronic mail facility was extended from human-human communication to computer-computer communication. These extensions were published as F.435 and X.435.
How does the IPMS get from a UA implementation to an MTA? In the 1984 version there was a ROSE-based protocol (P3) that allowed mail to be submitted or collected, but this was never implemented, and a UA was typically part of some MTA implementation, and used local interfaces to embed the IPMS protocol as a P1 contents. In 1988 (further extended from 1988 to 1992), the concept of a message store was introduced. With this concept, an MTA may be implemented alone on a system, may have collocated UAs in the old way, or may (and this is the direction implementations are taking) have supported on the same system a Message Store. When messages are to be sent, a UA uses another ROSE-based protocol (a set of ROSE operations, called the P7 protocol) to deposit the message in a local message store and to request its transmission. At the receiving end, the message goes into the Message Store. It is here that the value of the IPM headers becomes apparent. The message store is a very rich and active structure. The P7 protocol allows a UA to browse the messages that are waiting for him, making selections based on any of the header fields of the IPM definition. Moreover, the message store can be requested (through P7) to selectively (based on header fields), forward messages, delete messages, put messages in particular folders (group them together for easier inspection), and so on. Actions can be set up that are automatically applied when a new message arrives at the message store, as well as being performed by direct interaction from the UA.
figure 10.1: Message Handling System (MHS) components and interactions shows the model of interactions within X.400. There are still a lot of features that have not even been touched on in the above discussion. Two are worth a brief mention here.
{kind=link}
The first is interaction between X.400 and other services. In the 1984 work, there was a lot of effort put in to define the ability for a piece of X.400 mail to be sent to a suitable MTA and then sent out over either Teletex or Telex. This did not appear as a PTT service generally. More interestingly, in 1988, text was added to introduce the concept of Physical Delivery: once implemented, I could send from my office or home PC in the UK a piece of X.400 mail to my aged grandmother living at the top of a mountain in the USA, and have it printed out at the local post office at the bottom of the mountain. The local postman will then trudge up the mountain, deliver the mail, trudge down, and trigger the sending of a delivery notification. The specification carefully states that the printing of the mail is to be upside down, the letter automatically folded and placed in a "window envelope", so that the postman cannot see the confidential information that I am on my death-bed. Unfortunately my aged grandmother can only reply by an ordinary mail letter, and by the time I receive that, I am dead! In fact a very similar system (using vendor-specific protocols, not X.400) allowed parents in the USA with home PCs attached to E-mail systems to send mail electronically to their sons serving in the Gulf War. On arrival in the Gulf, it was printed off and then physically delivered.
The second area to discuss is security features. X.400 was one of the first standards to introduce (in 1988) a very strong level of support for security features. These were largely based on the use of so-called public key encryption techniques, and the X.500 series (published for the first time in 1988) provided substantial support for the distribution of the necessary encryption keys. The X.400 features broadly covered three areas: confidentiality (preventing unauthorised reading of part or all of a message), authentication (being able to guarantee who had sent it), and a variety of "proof of" exchanges. In particular, the UA can request from the Message Store/MTA a proof of submission, which is a package of (encrypted) information provided by the Message Store/MTA that the UA could take to a third-party judge (and which the UA cannot forge) to prove that a particular message was indeed submitted. Similarly, there are proofs of delivery exchanges. In the early 1990s, there was a lot of implementation interest in the security features of X.400, but significant implementations had not been widely deployed, and X.500 support for the distribution of public keys had not yet been implemented.
10.2 Directories (X.500)
Whilst X.500 (ISO/IEC 9594) is not as big as X.400 (it is four years behind: the first Recommendation was 1988, whilst for X.400 it was 1984; it may be that by 1996, they will be equally large!), it is still a substantial specification, and there are again complete books written about this alone.
From a protocol and conceptual point of view, X.500 is a very simple set of Recommendations. It is nothing more than a series of ROSE OPERATION definitions, with a number of ASN.1 datatype "holes" in the operations. The most significant set of "holes" are those used in the X.500 name, the so-called Distinguished Name, which is used for looking up information.
The X.500 system is essentially a single world-wide distributed database in which a bundle of information (an object entry) resides as a master copy on some computer system somewhere in the world. The object entry is nothing more than an unordered collection of ASN.1 datatype holes: a set of ASN.1 datatypes, each of which has an object identifier to identify its type and a datatype to hold its value. Again, there are ASN.1 macros defined to support the definition of the set of attributes of an object entry. A small number of attributes (like telephone number) have been defined, and object identifiers allocated, within the base Standard, but a particular object entry is neither required to contain these attributes, nor is it prevented from containing any other arbitrary attributes.
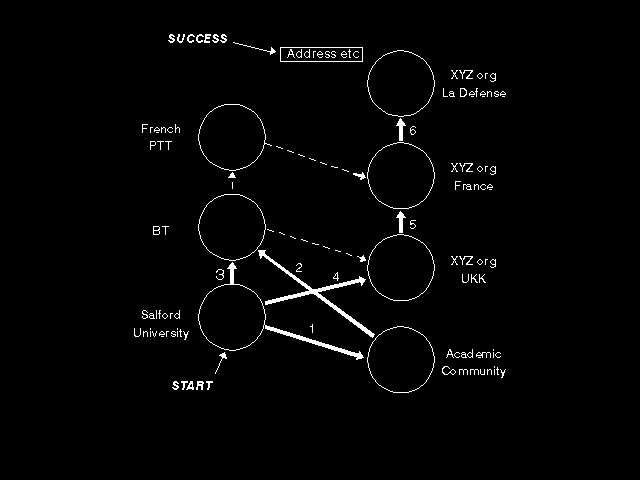
How does a remote system get information from an object entry? A key part of an object entry is a set of attributes (which must be present) called the distinguished name of the object entry. Thus an X.500 name is actual just a list of ASN.1 datatype holes! However, the attributes used to form the distinguished name are required to conform to a more specific structure, and a typical X.500 name would look like that shown in figure 10.2: A typical X.500 name. Here the parts before the equals sign are identifying the type of the attribute, and in transfer are represented by an ASN.1 OBJECT IDENTIFIER, whilst the parts after the equals sign are the value, and are carried in the corresponding ASN.1 datatype (frequently an ASN.1 "PrintableString" datatype). Much concern has been expressed about the character set to be used for attribute values in X.500 (remembering that it is providing a world-wide service), which had not been finally resolved by the mid-1990s. This name structure is used to navigate the so-called Directory Information Tree or Directory Information Base (the terms are interchangeable). For an artists impression (a fictitious but possible example), see figure 10.3: A name to be used for searching and figure 10.4: The search process. I receive the name shown in figure 10.3 on the back of someone's business card, and go to my local friendly X.500 implementation, type in the name, and say "Find dog, find!". The system at Salford gives a gulp, and says "Never heard of France, or of IBM, but I will ask a computer I know about that looks after a lot of object entries which contain information about the UK academic community, and knows about the location of others." It formulates an X.500 message (ROSE operation), and makes the enquiry ([1] in the figure). Still no luck, but that system knows about another system run by our friendly PTT (BT), and chains the request to the BT system ([2] in the figure). And now we are beginning to hit pay dirt: BT will not make calls on our behalf, but information has been lodged with it that the French PTT is a good place to go to find out about the location of object entries beginning with "C=FRANCE". Moreover, "OU=IBM" has been registered in almost all countries, and the BT system has also been told that enquiries about "C=XXX, OU=IBM" should be referred to a particular computer system in SALE, a town near Salford, for a wide range of XXX. The academic community machine thinks it has now done enough for Salford, and returns the information gleaned so far, together with the address of the system it got it from, so Salford has gained further knowledge about Directory Systems and the names they can handle and can cache that to speed future searches. The Salford system could now multi-cast to the French PTT and to SALE, but has enough sense to try the local call first ([3] in figure 10.4). And now we have hit pay dirt. SALE has a leased line to La Defense, the IBM headquarters in Paris, where a PC on the top floor contains the master copy of the entry I am trying to reach. Whoops: I mistyped the name - it should have been Mauhy, not Mahy. Never mind, fuzzy match, the hackers' paradise! (In fact, X.500 does include use of fuzzy matching, but not in relation to specific enquiries quoting a distinguished name, so a little bit of artistic licence was used in the above!)
{kind=link}
{kind=link}
{kind=link}
That little scenario has tried to illustrate in very broad terms the navigation of X.500 using the name. In fact, the master copies of object entries will normally be grouped together in groupings broadly related to name structure, but this is not a requirement. In principle, every single object entry could be located on a different computer system, and X.500 would still successfully navigate to it. Following the work in the early 1990s, shadowing arrangements can be set up for an object entry such that whenever it is changed, the changes are automatically distributed to a tree structure of shadows. Thus if system A frequently needs to refer to some object entry, it will attempt to position itself on the shadow tree for that entry. If it infrequently refers to it, it will navigate to the entry (perhaps caching the location of the entry) on each reference to the information.
There are two sorts of OSI-related information that X.500 might support. The first is the mapping from application-entity-titles to presentation service access point addresses, and the second is the (secure) distribution of certificates containing public keys that can be used to support security features in other applications, such as those present in X.400. In fact, the early prototype implementations of X.500 that were deployed in the early 1990's were used for anything but these purposes, storage and distribution of telephone directories being one common use.
The whole question of the eventual role of X.500 was not resolved by 1995, with a number of things it could be used for remaining contentious and being handled by other mechanisms. One area of discussion was the extent to which the holes in object entries should become presentation data value holes to support the storage and retrieval of more general material (images, video, voice, and so on) as attributes of object entries. This potentially brings X.500 into the area of a general wide- area information service, bringing it into potential conflict with the TCP/IP protocol of that name: Wide Area Information Service (WAIS), whose use developed during the 1990s. It is important to note here, however, that WAIS is oriented to retrieval of documents using natural language and full-text indexing of the documents to be retrieved, whilst X.500 is based on providing a very formalised name for the object entry that is being retrieved. Thus for many purposes X.500 will be unable to compete with WAIS, whilst WAIS is already used for purposes such as access to telephone directories that X.500 Experts consider to be a potential application for X.500.
Another question which arose in the early 1990s (and was not resolved when this text was written), was concerned with the trader for ODP (Open Distributed Processing). One of the concepts of ODP is that of location independence: access to some piece of functionality does not require knowledge of where in the network that functionality is being provided. To support this, the trader concept envisages a protocol which will enable a package to export its interface (announcing the availability of its services and their location), and a potential user then to request and to import that interface prior to connecting to and using those services. There were some Experts that contended that X.500 could be used as the basis for building trader support.
10.3 Remote Database Access
The work on RDA has a somewhat different focus from X.500. Here we are not talking about a globally distributed database, but rather about the somewhat simpler concept of remote access to a single computer system database.
The primary interest here is the infrastructure on which RDA is built. In particular, it uses ROSE for its operations and TP to provide atomicity. The Standard defines a Generic RDA which again is full of holes, and an SQL Specialization to produce an implementable Standard. (SQL - Structured Query Language - is the name for the ISO Standard for relational databases.) In early drafts, an ASN.1 macro was defined to fill the Generic RDA hole to produce the specializations, but when ASN.1 macros found disfavour, this was replaced by use of ordinary English.
10.4 File Transfer, Access and Management (FTAM)
FTAM was one of the earliest standards to be developed, and was mature long before ROSE and RTSE were discussed. Its development really dated back to the original thinking of monolithic specifications in the application layer, with no ASE concept. It almost became an International Standard without using A-ASSOCIATE (direct use of P-CONNECT), but at a relatively late date it was modified to use A-ASSOCIATE as the sole user of A-ASSOCIATE, using the nested service primitives model. It introduces a complete range of service primitives, including F-INITIALISE (mapped on to A-ASSOCIATE), F-DATA (mapped on to P-DATA), and F-P-ABORT (to reflect an upcoming A-P-ABORT) as well as FTAM-specific service primitives to open and close files for access (F-OPEN, F-READ, F-CLOSE) or (added much later) to transfer complete files (F-GET-FILE and F-PUT-FILE).
It was built on use of P-SYNC-MINOR and P-RESYNCHRONIZE for bulk data transfer, integrated into the main FTAM specification. There was an attempt made late in the development of FTAM to extract the data transfer text and to establish a New Work Item to develop a Standard for Bulk Data Transfer which FTAM could then be re-written to use, and which could be used by other standards, but by then work on RTSE was in progress, and the New Work Item proposal was turned down. Still later, there was a major controversy to try to get FTAM to modify its bulk data transfer phase to use the activity functional unit, and hence to align itself with (and/or to use) RTSE. This attempt also failed, so FTAM remains with FTAM-specific text, which is not usable by any one else, providing more or less the same functionality as RTSE. Many observers attribute the failure of this attempt to get FTAM to adopt the use of activities as the reason why CCITT/ITU-T has never (to this day) published the FTAM specification as a CCITT/ITU-T Recommendation, but has rather developed the DTAM (Document Transfer, Access and Management) and DFR (Document Filing and Retrieval Standards) both of which use activities, and both of which have functionality strongly overlapping that of FTAM. Nonetheless, in the early 1990s there was much more implementation interest and deployment of systems for FTAM than for both DTAM and DFR taken together.
The development of FTAM raised the big question: "What is a file?" In the file transfer protocols developed in the 1970s (prior to OSI), the answer was relatively clear: it was either a string of binary octets or a series of lines of text which were transferable either as ASCII or as EBCDIC. In the 1980s, particularly with the focus on file access, the model of a file was more difficult to agree. In particular, the ability to read and write (using FTAM) parts of the picture represented by a Computer Graphics Metafile (a standard for storing computer generated pictures), or of similarly structured files was one of the aims. Moreover, reading and writing parts of files when the material was written to a server by one system (with one form of representation of structures and characters) but read back by another with a different representation was considered important. This is broadly covered by the Presentation Layer concepts of abstract and transfer syntax, but meant that specifying the part of a file to be read or written had to be done in terms of the abstract structure, not in terms of the string of octets in some particular encoding of that structure. This is a similar (but not quite the same) issue to that of positioning checkpoints in the transfer of a file discussed in the section on RTSE.
In order to progress the FTAM protocol then, there needed to be agreement on what constitutes a filestore, in terms of the nature of a file's contents, any other associated attributes (such as the form of a filename, the date it was created and last read, access controls, and so on), and the nature of the directory structure. There was no International Standard available in this area, nor was it likely that if one was produced it would be accepted: filing systems are well-established, and are very varied in these areas. The FTAM approach was to define a Virtual Filestore, not as an attempt to standardise filing systems, but as a model on which protocol exchanges were designed to operate. An implementor would identify features of real systems that the implementation would map to the virtual filestore. If the virtual filestore was not rich enough, then vendor-specific protocols would remain, for there would be features of real systems that could not be mapped, and hence could not be reached by the FTAM protocol. On the other hand, if it was too rich, it would be impossible for any implementor to implement more than a subset of FTAM unless either the real filing system was modified to fit the FTAM Virtual Filestore model, or a complete new sub-filing system was built within an existing binary file, accessed only by the FTAM protocol handler. The latter is a possible option for a dedicated LAN file server, but is otherwise unattractive as local utilities, editors, compiler run-time systems, etc would all need to be modified to access files in the real Virtual Filestore. In fact, the attempt was made (particularly in relation to file attributes) to make FTAM as rich as possible, but to give good support for implementors that could only implement a subset. The reader should bear this in mind as the following text is read.
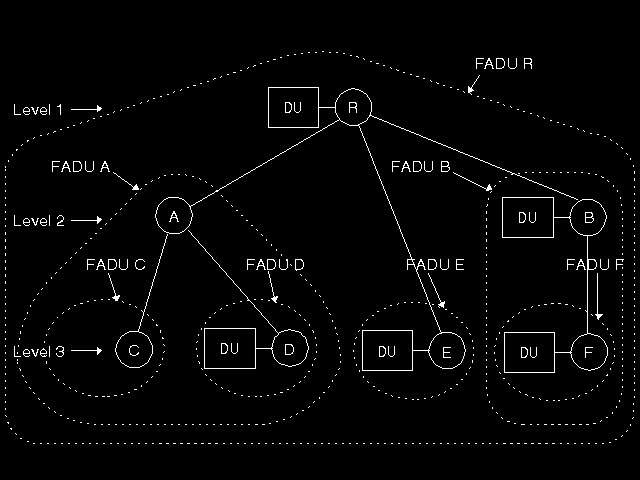
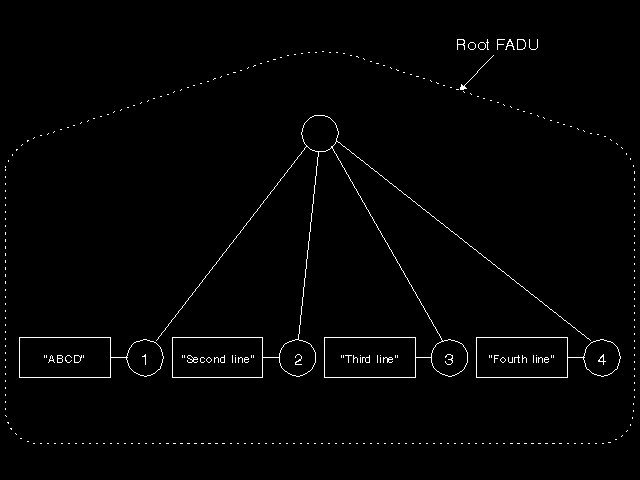
One of the most important parts of the FTAM Virtual Filestore model is the model of the contents of a file. This is illustrated in figure 10.5: FTAM contents. The file is based on a tree structure (and we do mean the file contents here, not some directory structure), with a root node, nodes beneath that, and so on, to any depth. Each node is potentially named (we will ask later what is the form of the name), and each node has associated with it a possibly empty Data Unit (absence of a Data Unit and an empty Data Unit are the same thing). Again, we will see later what a Data Unit is. The unit for access is the FADU (File Access Data Unit), which should not be confused with a Data Unit. There is an outer level FADU that consists of the entire file's contents, and nested FADUs for every possible subtree of the tree structure. Thus, using FTAM, any subtree (FADU) can be read individually, deleted, replaced, or a new complete subtree added anywhere in the structure. (FTAM also allows any Data Unit to be extended.)
{kind=link}
Let us address the node names and the Data Units. What are these? Perhaps the reader can guess. They are holes! The node name is a presentation data value from some abstract syntax. Each Data Unit is an ordered list of presentation data values from one or more abstract syntaxes. How is all this mapped to what we conventionally think of as a file, and in particular to the fairly simple sequential structures (perhaps with random access) that we are used to for lines of text files and so on? There are two important steps. The first is to restrict the general hierarchical model in useful ways to fit particular actual file structures and access requirements, and the second is to fill in the holes by specifying actual abstract syntaxes.
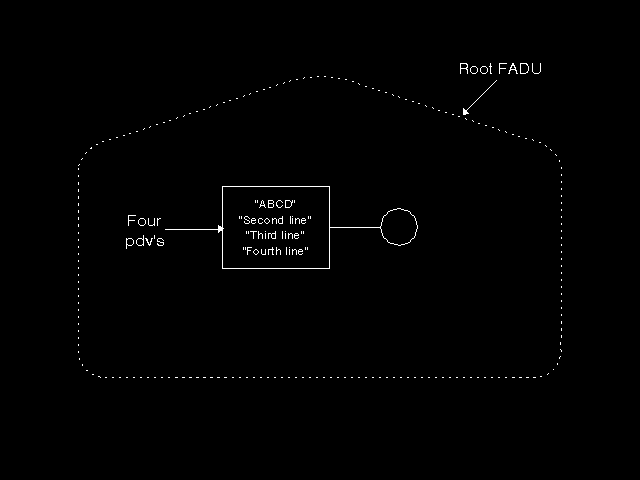
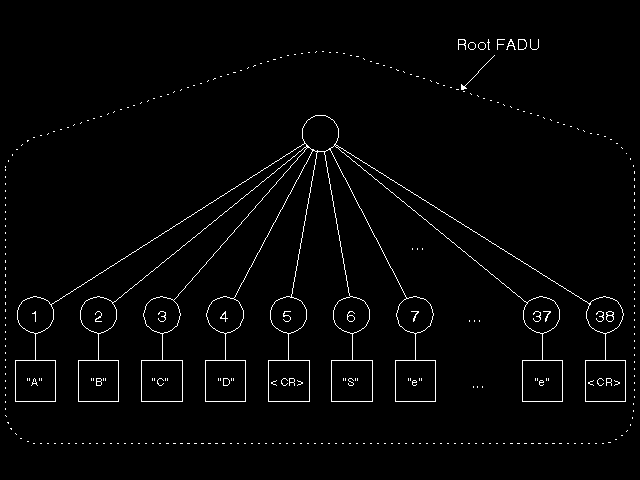
FTAM defines in the Standard (and identifies with ASN.1 OBJECT IDENTIFIERS) a number of constraint sets to restrict the hierarchical model. The simplest constraint set is the unstructured constraint set. In this case, there is a root node only, with no name, and no child nodes. Thus the only operations possible are to read or write the whole file, or to append more presentation data values to this root Data Unit. This is illustrated in figure 10.6: File contents (unstructured). If an implementation supports only the unstructured constraint set, then FTAM file access becomes particularly simple, and in particular there would be no support in the implementation to any form of random access to files. Another constraint set is the flat constraint set, where there is a root node with no name and no Data Unit, and child nodes all of which are required to have (non-empty) Data Units. In the simplest possible definition of an FTAM file, a constraint set is specified plus a single abstract syntax that contains the values that can be used for node names and elements of Data Units. In practice, however, this is rarely used. FTAM goes further and introduces the concept of a Document Type, which is identified by a single object identifier, and consists of fairly stylised English text specifying precisely the constraint set in use, the abstract syntaxes used (more than one is possible), and any additional restrictions. Thus, for example, if we specify the flat constraint set, require each Data Unit to contain precisely one presentation data value of ASN.1 type VisibleString, and have node names that are numbers and serially number the nodes that are children of the root, we have straightforwardly (!) got an ASCII text file with random access to the lines of text, allowing reading of any individual line or series of lines, and insertion of a new line of text or series of lines of text at any point. (See figure 10.7: Modelling a random access text file). On the other hand, if we specified the unstructured constraint set and the same set of presentation data values (with the single Data Unit now containing arbitrarily many presentation data values), we have the same ASCII text file, but with only the ability to read it as a whole or to append new lines of text at its end. (See figure 10.8: The same text without random access). Clearly, a file which is actually supported for random access could be made to look like the simpler form for access by some systems. This is called a simplification of the Document Type into another Document Type. All permitted simplifications are defined when the Document Type is defined, and FTAM supports reading (but not writing) a file using a defined simplification of its actual form. The above Document Types would be different again if the presentation data values were restricted to a single character from a character set that would includes an encoding of carriage return as well as printing characters (see figure 10.9: Random access to individual characters). We now have a file modelled as a simple sequence of these characters with, in the one case, random access to each character, and in the other only the ability to append new characters to the end of the file. By contrast, the full power of the hierarchical structure is needed to represent the Computer Graphics Metafile abstract syntax.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
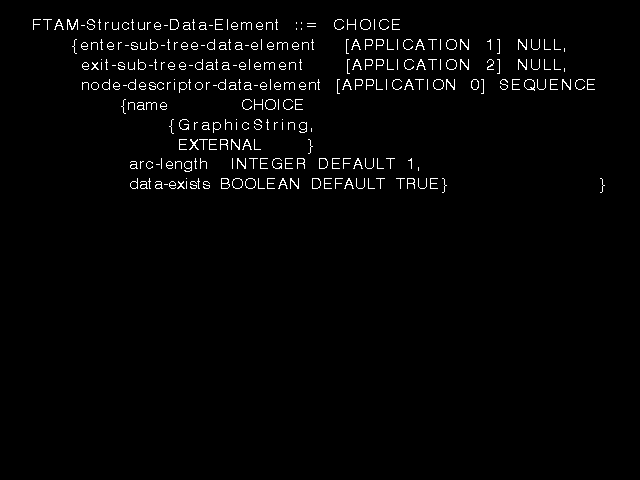
Suppose we want to transfer a FADU (the whole file or some part of it), either to read a FADU, to add a new FADU somewhere in the tree, or to replace a FADU, how do we transfer a tree structure? FTAM defines a flattening of the file for transfer. The transfer requires the establishment of a presentation context for an FTAM-defined abstract syntax called FTAM STRUCTURE which is the values of the ASN.1 type shown in figure 10.10: Type for FTAM STRUCTURE abstract syntax. This provides values "up", "down", and "node-info" that carries a node name (the EXTERNAL), a boolean flag specifying the presence or absence of a Data Unit at that node, and an integer containing an arc length. (FTAM has the concept of a child node sitting at some particular level beneath its parent - the arc length - not necessarily immediately beneath it; this is the long-arc concept discussed later.) It is also necessary to have presentation contexts for node names, for any presentation data values appearing in Data Units, and for those needed for node names. (FTAM uses only the presentation context identifier form of the EXTERNAL.)
{kind=link}
The transfer of a FADU consists of a simple list of presentation data values which can (unless checkpointing is needed) be carried as the list of presentation data values in the user data parameter of a single P-DATA. If checkpointing is needed, the list of presentation data values can be split between one or more P-DATA primitives, and P-SYNC-MINORs inserted. The first presentation data value in the list is "down" to enter the FADU, then a value of "node-info", giving the node name of the root node, its arc length from its parent (zero in this case) and flagging the presence or absence of a Data Unit at the root node. If a Data Unit is present, the presentation data values in that Data Unit are next in the list. Then there is a "down", transmission in a similar way of the FADU of the child (recursive application of this description), then an "up", then another "down" to the next child, or an "up" if no more children, to complete the transfer of the FADU. Thus we see that the end of the list of presentation data values in the Data Unit is determined by the presence of an "up" or a "down" from the FTAM abstract syntax. It can, however, happen that a presentation data value in the file may be a value from the FTAM-defined abstract syntax used for "up", "down" etc. This could, for example, occur if the file was a log file that had been logging the values transferred in an FTAM transfer. To prevent any danger of confusion of data contents with a real "up", "down", etc, a presentation data value being transferred is only interpreted as an "up", "down", etc for this transfer if the presentation context is the first defined presentation context for the FTAM-STRUCTURE abstract syntax, preventing any ambiguity. Thus it can be seen that FTAM fully embraces the Presentation Layer concepts of abstract and transfer syntax, and indeed uses them heavily to provide transparent transfer of file contents.
There is only one other major issue to discuss in relation to FTAM, and that is the question of file attributes. Many operating systems keep additional information (typically notionally part of some directory entry) with a file. As well as the file name, there is often the size of the file, the date (and time) it was created, perhaps (for a multi-user system) the identity of the creator, and an access control list. Operating systems differ very much in the nature of the file attributes they support, and it is not easy to see what should be supported by the FTAM standards. The reader will recall a similar problem for the header fields of an Interpersonal Message in X.400. In the first version a limited set of headers were hard-wired into the protocol: later, ASN.1 datatype holes were added to allow easy addition of new headers. FTAM in fact has not (as of 1995) progressed beyond the hard-wired stage for file attributes. There is a set provided that is believed to be sufficient for most systems, with significant support for implementations to handle only a subset. They can agree (via negotiation on F-INITIALIZE) that "We are not going to talk about values of this group of attributes", and a responder, when asked for the value of an attribute in a group that they have agreed to talk about, can say "Sorry, no value available".
Finally, we will mention briefly some of the extensions to FTAM that occurred in the early 1990s. We discuss below directory structure, service enhancement, overlapped access, and security.
The initial FTAM Standard contained no text related to the directory structure of the Virtual Filestore. This was deliberate in order to progress the Standard quickly (it still took close to ten years!). An addendum in the early 1990s added support for directory structure, and in the process changed the notation for file. We now talk not about files, but about file objects! We also have directory objects and reference objects. The structure will be fairly familiar: directory objects contain file objects, other directory objects, or reference objects. Reference objects point to directory or file objects anywhere in the Virtual Filestore. All objects have most of the attributes previously associated with files, in particular date created, creating user, and access control lists. One of the interesting side-effects is that the ability to access a file can depend on the route through the directory structure that is taken (using reference objects) to reach the file.
In the original FTAM Standard, to transfer a file it was necessary to issue a number of primitives to select it, open it, position at the desired FADU, transfer the data, end the transfer, close the file, deselect the file. (This does not imply a lot of round-trips: some of these primitives are unconfirmed, and some of the resulting messages can be carried in the same P-DATA, but the service description looks complicated, and can be messy for any Standard using FTAM to specify). Moreover, where implementors take service primitives as a model for implementation interfaces (which they shouldn't, but ...) this can make FTAM appear very complex. The service enhancement addendum made no change to bits on the line, but merely added two additional service primitive interactions that invoked everything necessary to read and write a single file: F-GET and F-PUT.
The overlapped access addendum is particularly interesting, in that the primary specification is written in the LOTOS FDT language (see chapter 3), with the English language text being mainly descriptive. Whilst FTAM in principle uses an association in a two-way simultaneous manner, in practice a lot of the time it is a one-way flow, particularly when a file is being transferred. This addendum enables requests for any FTAM operation, possibly involving the reading and the writing of data, to be stacked up, with each request processed only when that particular direction of flow becomes free and permits the request to be satisfied. The reader will recognise the complexity of the resulting State Table, and hence the reason for using an FDT to specify this annex. The service enhancement providing F-GET and F-PUT helps in visualising what is going on. A system accessing a file server using FTAM can stack up a number of F-GET requests and a number of F-PUT requests, and they will be serviced in turn, ensuring a continuous flow of data in both directions simultaneously. The complications of this arise mainly from the problems of checkpointing and recovery after crashes! Opinions differ on the importance of driving an application association in a two-way manner. It would clearly be possible in theory to set up two separate session connections multiplexed onto a single transport connection (classes 2, 3, or 4), and to use one for F-GET requests, and one for F-PUT requests, thus achieving two-way flow over the actual medium, but keeping FTAM simple. But you could not do that over classes 0 or 1! Readers must form their own views!
We have not discussed the FTAM Access Control List in detail, but it is a very rich structure. It allows access controls to be based on the location (application-entity-title, authenticated by the addendum to ACSE) from which the access is being requested, the identity of the accessing user (based on a password carried in F-INITIALIZE), or on a set of eight passwords, one each for the different sorts of actions that might be attempted (reading the file, deleting the file, changing attributes, and so on). The granularity of control is also at the level of these eight possible actions, so permission to read attributes can be given without giving any other access to the file. There are a number of flaws: first, apart from the ACSE authentication of the AE-title, the authentication is all by a simple password, vulnerable to a line monitor, not an encrypted exchange; second, there is no ability to give blanket access permissions, then to exclude particular users, and finally, despite the eight actions that can be separately controlled, it was not possible to separately control the ability to change the access control attribute from the ability to change other attributes. In the late 1980s, a short study showed that these flaws (particularly the last two) would prevent a file-access implementation based on FTAM from getting any sort of security classification under a very common test based on something colloquially called the DoD Orange Book (more formally "Department of Defense Trusted Computer System Evaluation Criteria"). This resulted in a New Work Item to look more closely at the security features of FTAM, and resulted in the early 1990s in a more substantial report on what was needed, what could be regarded as FTAM-specific, and what was better progressed in a way which would be applicable to all applications. The final outcome of this work was not clear by 1992.
10.5 Virtual Terminals (VT)
The work to produce standards supporting terminal access to remote computers was again one of the earliest OSI standards to be commenced, and started in the days of dumb terminals. The work made little progress for several years, as a result of differing views of an appropriate model of terminal communication.
The first model stems from the CCITT X.3, X.28, and X.29 specifications (often called triple-X), originally produced at about the same time as X.25, and supporting dumb terminal access over X.25 to remote machines as if they had been directly connected. In its day it was a very important set of standards, providing the bulk of early X.25 use. The triple-X protocols are not OSI protocols: X.29 sits directly on top of X.25, and uses the Q-bit feature of X.25 which is absent from the Network Service definition. (The Q-bit is a one-bit field present in every X.25 data message, but whose use is not defined in X.25: rather, it is left for the application using X.25 to specify its use - in the case discussed here, X.29). The triple-X model is shown in figure 10.11: Triple X model. Here we have an X.25 connection between a host and a PAD (Packet Assembler Disassembler), used in accordance with X.29. The PAD has an asynchronous line connection to a dumb terminal (often dial-up over a modem), and receives characters from the keyboard typed by the human hand, and sends characters to the screen, seen by the human eye-ball shown in the figure. The PADs main function is to stack up characters received from the keyboard until it is appropriate to forward the packet across the network (usually as the result of the arrival of a carriage return character, but it could be time-out or various other rules), and to receive packets across the network and send them as a series of characters to the screen. This gives rise to its name. A number of parameters (specified in X.3) control the operation of the PAD. In particular the echo parameter determines whether the PAD also copies all characters received from the keyboard back to the screen. Other parameters relate to forwarding conditions and to the insertion of carriage returns in output to provide line-folding of long lines (very necessary on the oldest dumb terminals called teletypes). The X.29 protocol uses the Q-bit to identify an X.25 message either as material for the screen or from the keyboard, or as messages allowing the host to read and write the X.3 parameters in the PAD. The X.28 Recommendation was essentially a user interface specifying how a user could read and write the X.3 parameters in the PAD from the terminal. Anybody accessing a remote database over an X.25 network in the 1980s and early 1990s is likely to have been using triple-X. This then, was one possible model on which to build the Virtual Terminal protocol. Note that in this model there is a two-way simultaneous use of X.25, one direction taking keyboard data, the other data going to the screen.
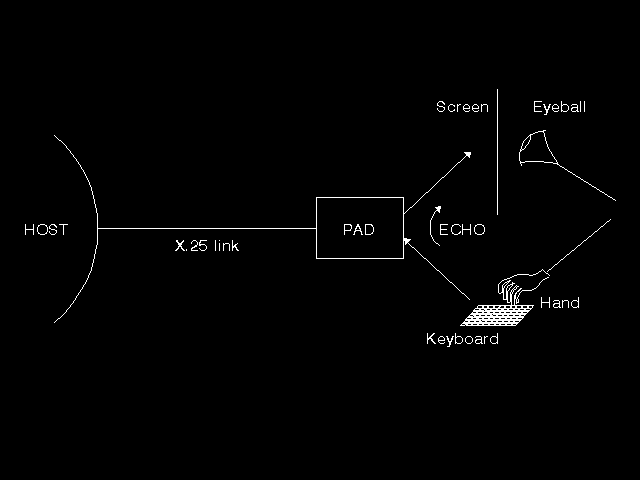{kind=link}
The second model proposed was rather more abstract (see figure 10.12: Symmetric model). In this model, the terminal-end and host-end are simply two pieces of intelligence, and are indeed symmetric. In the middle of the communications line there is a glass screen, and each piece of intelligence has both a paint-brush that can be used to paint the screen and an eye-ball that can be used to view it. The main thing to worry about is that both sides should not be allowed to paint the same part of the screen at the same time, so we need some sort of token control. The simplest approach would be to control at the level of the whole use the Session Layer token (TWA use of session) to provide the control.
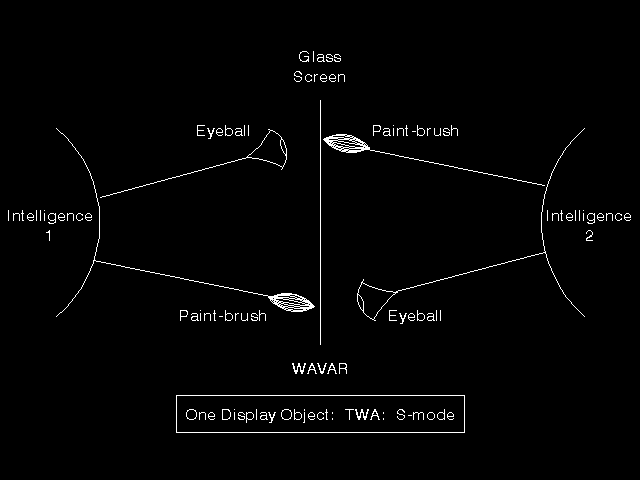{kind=link}
How can these rather different models be combined/reconciled? Suppose we move the PAD into the centre of the communications line, and recognise that it provides essentially two independent one-way flows, with the "echo" capability cross-connecting them. We will worry about other parameters later, but very many of the X.3 parameters are concerned with line-folding and similar matters that are irrelevant once we accept intelligence at the terminal end, rather than a dumb terminal. We can redraw the PAD model as shown in figure 10.13: Revised PAD model. Now we have two glass screens in the middle of the communication line, and one end is restricted to painting on one (and viewing the other), whilst the other end paints and views the other one. Apart from the echo path, this is a simple two-way flow. Of course, the Standard does not talk about glass screens, it talks about Display Objects. These two models now look a lot more similar to each other than was the case when we used the original PAD model, and perhaps we can now reconcile them in a single Standard. Remember the adage "If you can't agree, make it optional ....". And so we get, in the VT Standards, two modes of operation, either or both of which can be implemented by implementors, and which form effectively two non-interworking VT Standards packaged in the same text. In A-mode (A for asynchronous), we have TWS operation of session, two Display Objects, and what it calls an Echo Object that can be written to by either end to determine whether echoing takes place or not. The access to the two display objects does not vary - one is writable by the initiator of the association, one by the acceptor of the association. We have WACI/WACA (pronounced "wacky wacka", a lovely phrase!) access control (Write Access Controlled by Initiator/Write Access Controlled by Acceptor). In S-mode (S for synchronous), we have TWA operation of session, a single Display Object, and no Echo Object. Access control is WAVAR (pronounced "wave-ah") (Write Access Variable), and is controlled by the positioning of the session token. (The reader may find it easier to remember all this if it is noted that the A-mode is TWS and S-mode is TWA!)
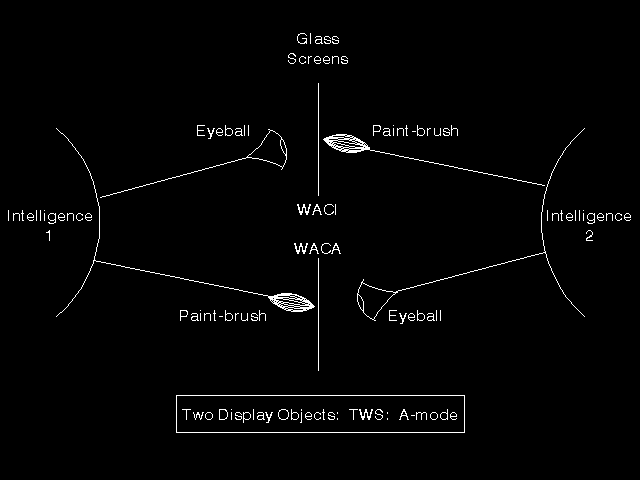{kind=link}
Readers who have used (dumb) terminals connected to a host, will be aware of two styles of operation: one major computer manufacturer locks the keyboard when the system has control of the screen, and unlocks it only when you are able to type. This is essentially S-mode. Another major computer manufacturer leaves the keyboard unlocked at all times, and what is typed gets mixed up with any output currently going to the screen in a fairly random way. This is A-mode. Interestingly, early in the 1990s there seemed to be more implementation interest in A-mode than in S-mode.
So much for the model. But what exactly was the nature of a Display Object (the glass screen)? It was a simple character box device, with foreground and background colours, with one, two or three dimensions of cells containing characters. The precise number of dimensions and size, the number of foreground and background colours (and the actual colours), the number of levels of emphasis (and whether these were flashing or double intensity) were all matters that were negotiated between the two ends. Most of the complexity of the initial VT Standards was in the negotiation of the mode, parameters of the display object(s), and the existence of control objects (as well as Echo, there can be control objects called "function key n", or "on/off", or "beep" - in other words, facilities for out-of-band signalling). In order to ease this negotiation task (and to give it some chance of succeeding!), the VT Standards introduce the concept of Terminal Profiles (collections of these parameters) which are identified (you must have guessed!) by an ASN.1 object identifier. In fact, a machine-readable language has been defined to specify terminal profiles, and a glint in the eye of the VT group is that implementations could be made quite flexible by looking up (using the X.500 Directory service) the meaning of any Terminal Profile object identifier value that they were offered, without having to have it hard-wired into the implementation.
Let us finish this brief overview with a short scenario. An intelligent terminal connects to a host. There is negotiation of the terminal profile to be used (establishment of the Virtual Terminal Environment (VTE)), and the screen comes to life as a very basic black and white screen for the login dialogue. Once logged in, a profile associated with the user name in the host is used to negotiate a new (scrolling) terminal environment with a single foreground and a single background colour, but no longer black and white, forming a new VTE. The user then invokes a graphics package, and suddenly the screen comes to life in many colours - a new VTE has been negotiated. When the use of the graphics package is completed, that VTE is destroyed, and the scrolling VTE of the command processor is reinstated, with the screen in the state it was left in when the graphics package was entered. A new package can now be entered, and another VTE negotiated. Notice finally that if an application wants a very large screen, it is a local matter for an intelligent terminal end to provide local controls to window onto that: it is not necessary to refuse a VTE if the screen the application desires is larger than the actual physical screen on the terminal.
This brings in the whole question of windows, and indeed of raster and geometric graphics rather than simply character cells. In the early 1980s, the work described above was called Basic Class Virtual Terminals, and more advanced support was planned. Such work was never progressed, and VT remains a character-box only protocol. As a character box protocol, however, a number of support features have been added as addenda that make it quite powerful for form-filling applications. In particular, a forms (screen) design (with protected fields and stated forwarding conditions when certain keys are pressed) can be invoked at the terminal end, either by sending it down the line or by sending an ASN.1 object identifier to invoke one already known at the terminal end. Thus all the work of handling the completion of the form is exported to the terminal end, with only the characters eventually filling the form being sent up the line to the application. This can enable an application to handle a large number of terminals for this sort of application, compared with (for example) the use of X- windows for the same purpose.
In the late 1980s, work on Terminal Management was introduced to begin to address the question of multiple windows, each potentially associated with a different server. This work never progressed, was overtaken in the early 1990s by work intended to lead to the standardization of X-windows over the OSI stack, and was subjected in 1992 to a formal review process designed to abandon the Terminal Management work. Thus in the early 1990s, it looked as if the choice for terminal handling in OSI would for some time remain either the efficient character-box-oriented VT Standard, or the X-windows over the OSI stack Standard for more general activity.
The VT Standard, as might be expected from the date the work was started (late 1970s), is a monolithic Standard, making no use of ROSE or of RTSE. (RTSE is probably not relevant to VT, and ROSE would probably have introduced too many overheads on the individual character transfers that tend to be characteristic of advanced terminal handling, so this is probably a good thing!) In contrast to FTAM, it does not "steal" A-ASSOCIATE, but rather assumes that an association with the right properties has been established for its use. Thus it fits a little more easily into the XALS structure. VT makes use of many session services, including major synchronization, resynchronisation, expedited data, and orderly release.